
Hur ser du idag på den information som presenteras för din besökare på webben? Förhoppningsvis är det en välkomponerad mix av allt besökaren behöver, oavsett vilken källa informationen ursprungligen låg i.
Allt för ofta ses webben som en plats för redaktionellt arbete med material som ledningen vill få ut illa kvickt. Ett avsändarperspektiv snarare än ett mottagarperspektiv. Med god informationsarkitektur kan en webbplats fungera riktigt bra. Genom att märka upp information blir det möjligt att få webbplatsen och andra informationskällor att samverka så webbplatsen alltid är aktuell och relevant.
Informationsarkitektur handlar om hur information organiseras och är åtkomlig för att den ska kunna göra verklig nytta. För att information ska kunna göra nytta behöver den användas av någon som behöver den, så hur designar man sina egna informationskällor och vidareutnyttjar data som andra delar med sig av för att uppnå ett mål? Hur uppnår man samverkan mellan de olika informationsmängder som krävs för en modern webbplats?
Webben ligger av historiska skäl lite efter andra informationssystem inom detta område. I min mening beror detta på att webben, och intranät i ännu större utsträckning, fram till nyligen setts som skyltfönster snarare än en del av den faktiska verksamheten. Webbplatser har inte alltid varit lika funktionella för den tilltänkta målgruppen som en postorderkatalog varit eller självservicekassan i en matbutik.
Nu börjar insikten att webben kan tillföra ett betydande värde slå rot hos de flesta och för att webbplatsen ska kunna göra skillnad krävs god informationsarkitektur. Det är vad detta ämne handlar om.
Ordlista – Metadata alternativt beskrivande metadata:
Med metadata avses för det mesta data om data eller information som beskriver annan information. Det kan exempelvis vara indelning i kategorier eller nyckelord som beskriver innehåll. Ordet meta kommer från grekiskan och betyder mellan, efter eller över. Metadata är oftast data på ett högre abstraktionsplan än den data den beskriver.
Innehållskoreografi
Innehållskoreografi handlar om hur man återanvänder och styr information baserat på data och metadata. Är inte informationen fri, i ordets alla bemärkelser, är den inte så lätt att återanvända. Tekniska aspekter kan spela in i hur fri och återanvändningsbar information är. Jag skulle dock tippa på att det största problemet är att man saknar vetskap om sin information och missar att ställa relevanta krav på hur den ska kunna användas av andra, för att inte tala om att återanvändas av en själv, vid ett senare tillfälle i ett annat sammanhang. Många gånger är man inte tillräckligt långsiktig när innehåll skapas för att se vilka behov man kan komma att ha under innehållets levnad.

Ett av dessa andra sammanhang som varit en vanlig utmaning de senaste åren är hur man fyller både en webbplats och en mobilapp med innehåll utan onödigt dubbelarbete. Det finns bland annat tekniska hinder som att man använder HTML för att paketera innehåll på webbplatsen vilket inte är det naturliga sättet att erbjuda innehåll i en mobilapp. Alltså är det inte riktigt så enkelt som att låta webbpubliceringssystemet i ett oförändrat skick stå som källa för allt innehåll man erbjuder i sin mobilapp.Innehållet kan behöva vara lite annorlunda på en mindre skärm för att fungera tillfredställande och designkonventionerna är inte identiska. Exempelvis är text som är blåfärgad eller understruken inte en lika självklar genväg till annan information i en app som på webben.
Ordlista – Taggar, nyckelord, etiketter:
Ett eller flera enskilda ord som beskriver eller lyfter fram viktiga ord från en text.
Ordlista – Taxonomi:
Klassificeringssystem, ibland med en trädstruktur, för gruppering av saker som är lika, har samma ursprung etc. Likt zoologi där kattdjur är en av flera grupper av djur inom gruppen däggdjur.
Något du säkert sett på webben är att man kompletterat den vanliga meny-navigeringen med sätt att hitta information som liknar det innehåll du har framför dig. Det är särskilt vanligt på webbplatser baserade på WordPress att man har kategoriseringar och taggar som dels beskriver innehållet men också ger en länk till en lista med liknande innehåll på webbplatsen. Det finns en stor variation på denna typ av dynamiska navigation som skapar en struktur och kompletterar en mer ordinär vanlig meny med ett sätt att istället följa informationens ämnesmässiga släktskap. På webbshoppar ser man ofta att menyn tycks vara en mix av en vanlig meny och något som är drivet av taggar. Man kan ofta hitta en produkt i flera olika listningar baserat på tillverkare, typ av produkt, dess färg, storlek med mera.

Men taggar kan också vara dolda för de vanliga besökarna av en webbplats och ha en mer verksamhetsintern användning. Själv har jag använt dolda taggar för att ange en prioriteringsnivå för årlig uppdatering av text, exempelvis prio2, och annat där intern taggning gjort att systemet inte behövde modifiering för att stödja nya användningsområden. Har fungerat lite som en intern anteckning för alla med behörighet att ta del av intern information. Behovet av en taxonomi är kanske inte uppenbar förrän någon frågar sig vad prio2 innebär, men i andra fall är istället taggsystemet väldigt uppenbart då det är synligt på den publika webben vad som händer med innehållet. Främsta poängen med taggar är att dynamiskt kunna använda innehåll och underlätta återanvändning senare. Precision i förståelsen av vad varje tagg avser gör det lättare att våga ta beslut om återanvändning enbart baserad på taggarna, så tvekar du kring dina ord bör du upprätta en taxonomi. Det är heller aldrig för sent att börja tagga befintligt material om man ändå redigerar det, i vissa fall kan man automatisera taggningen baserad på någon annan information som redan finns – förekomst av nyckelord i brödtext exempelvis.
Information som inte kan återanvändas riskerar att behöva kopieras till ett nytt system – och då får man minst två versioner som behöver uppdateras vid förändringar. Detta problem försöker man adressera med innehållskoreografi, att se till att värdefull information är lättrörlig, mångsidig och användbar i alla nödvändiga sammanhang. Ibland är det lättare att sätta fingret på utmaningen om man tittar på exempel där något gått snett, det är precis vad vi ska göra nu.
Exempel på dålig innehållskoreografi
Det mest klassiska exemplet är det där systemet som beställs och kravställs av en icke-representativ minoritet av de framtida användarna. Ibland kan denna minoritet vara det fåtal som är högljudda eller klarar av att konkretisera sina krav. Låt säga att personalavdelningen behöver ett nytt HR-system. Behoven beskrivs och ett system upphandlas. Vinnaren är ett system som har en extrafunktion leverantören kallar för självservice, en enligt leverantören smidig ingång i HR-systemet där alla medarbetare kan rapportera in sin arbetstid, ansöka om ledighet med mera.
Problemet är att nu använder alla anställda ett system vars primära mål aldrig kan bli att vara användbart för de som inte behärskar personalfrågor. Magplasket är ofta oundvikligt och resulterar i frustrerade medarbetare som slösar tid på ett system de skulle undvikit om de inte var tvungna att använda det.Hade man i kravställningen bevakat att innehållet skulle kunna samverka med andra informationssystem hade det troligen blivit billigare att
senare skapa ett specialiserat gränssnitt, exempelvis på intranätet eller som app, för det fåtal aktiviteter majoriteten behöver utföra.
Ett exempel på problem liknande detta drabbade mig själv när jag skulle redigera start- och slutdatum för när jag skulle vara deltidsledig från mitt jobb. Det fanns ingen möjlighet till redigering av befintliga poster vilket ledde till att jag raderade denna post från HR-systemet för att sedan lägga in en ny post. Morgonen efter ringde en ilsken person från HR-avdelningen upp mig och frågade varför jag raderat det arbetsschema hen mödosamt hade skapat åt mig. Att det fanns ett schema kopplat till min ledighet kunde jag varken se eller veta om att den hängde ihop med det jag gjorde. Hade jag fått välja hade jag gärna sluppit veta om HR-folkets system över huvud taget och gjort de enkla uppgifterna jag behövde göra via ett simpelt webbformulär på intranätet. Vad som händer när man postat formuläret borde inte vara den enskildes bekymmer utan något som HR manuellt, eller allra helst via ett bra verksamhetssystem, tar över ansvaret för. Min enda syssla i detta ärende var rapportera in ett startdatum, ett slutdatum och en procentsats för andel frånvaro. Istället för ett aktivitetsdrivet intranät med bakomliggande stödjande informationsmodell erbjöds ett system där alla anställda är sekundära användare. En extra inloggning, letande bland HR-begrepp i navigation för att hitta ett formulär som tydligen bakom kulisserna har relationer till saker jag inte har att göra med.
Det är kanon att min ledighetsansökan har kopplingar till besläktad information. Det är dock under all kritik att man inte kunnat identifiera hur denna verksamhetsprocess ska ske på ett intuitivt och förutsägbart sätt för alla inblandade. Det här är förstås inte min arbetsplats ensam om.
En annan välkänd variant av bekymmer för användarna är när man har flertalet system för att lösa en enskild arbetsuppgift. För byråkrater är det inte ovanligt att man har flertalet dokumenthanteringssystem att välja på för att lagra undan ett nyskapat dokument. Osäkerhet uppstår förstås i vilket av systemen man ska leta rätt på ett dokument i efterhand. För att inte tala om att i en ytterst trolig framtid ha flera dokumenthanteringssystem att avveckla under kontrollerade former med överföring av innehåll till ett nytt system.
I andra fall innebär frånvaron av innehållskoreografi en utdragen process med massor av olika system som man behöver växla mellan för att bli klar med en arbetsuppgift. Exempel på detta rapporteras ofta, särskilt under krigsrubriker, som att läkarna på grund av nya system inte har tid med patienterna längre. Varje system är omedvetet om sitt bidrag till vad användaren försöker åstadkomma och de vet sällan om något användaren just matat in i ett annat system i samma ärende eller process. De följer inte samma standard för hur exempelvis personnummer ska matas in, vilket blir en av många saker att försöka komma ihåg, förutom själva personnumret, mellan varje system man växlar mellan för att försöka få jobbet gjort.
Inte heller kan man förvänta sig att det räcker med att logga in en gång, det kan man bli tvungen att göra flera gånger inom några få minuter då systemen inte delar inloggningssession. Som grädde på moset har ofta system olika krav på lösenords komplexitet vilket leder till att man som användare har olika lösenord att ange beroende på vilket system som frågar. Här uppstår förstås en rejäl dos stress, dålig stämning och tveksam upplevelse bland användarna.
Lösningen är ofta både enkel och uppenbar, i detta fall ska man fokusera på användarupplevelsen av innehållet först – upplevelsen av innehållet i alla de sammanhang den kommer finnas under sin livslängd. Med andra ord är inte innehållet så sekundärt som det tyvärr ofta blir i projekt. Strukturerat innehåll kommer överleva flera versioner av ett system och vara redo för att följa med in till nästa system. Det gäller att försöka undvika möjligheten att vara efterklok – common sense is not common practice…
Där god innehållskoreografi råder finns vissa ingredienser representerade i olika stor utsträckning, exempelvis:
- Allt material är beskrivet med hjälp av metadata så system kan veta vem som är en tänkt mottagare och i vilken situation.
- Systemen anpassar sig efter användarens process och behov – inte tvärt om.
- Illusion om att man bara har ett enda system.
- Information följer med användaren.
- Dubbelregistrering av data behövs inte.
- Informationen är relevant utifrån mottagarens förkunskaper, preferenser, plats med flera personaliseringsfaktorer. Rätt information vid rätt tillfälle för att stilla ett visst behov.
- Information följer ett och samma format, exempelvis datum, allra helst en internationell standard.
- Kontextuellt stöd för att utforska relaterad information. Det kan vara att hitta besläktat material, mer översiktlig information eller kanske en lista över vilka detaljer det finns mycket extrainformation kring.
Nu kommer vi gå igenom några delområden för att ha ordning på sin information.
Master Data Management för att inte duplicera i onödan
Ordlista – Master Data Management (MDM):
Det systematiska arbetet en organisation har för att hålla koll på sin referensinformation. Kan vara snuttar som organisationsnummer, till att ha stora register med kunders beställningshistorik.
På en publik webbplats finns ofta information som inte webbplatsen per definition äger. Det kan vara kunduppgifter, prislistor, produktinformation etc. Denna information kan vara något med ursprung från ett internt verksamhetssystem i stil med kundhanteringssystem eller ekonomisystem. För produktinformation kan det vara något man får löpande via leverantörers system. För ett intranät är det inte ovanligt att man har information om prisbasbelopp (justering för inflationen i samhället), löneutbetalningsdagar och behörigheter till information. Dessa data kallas ofta för referensdata och dess hantering går under begreppet Master Data Management (MDM eller MDM-system).
Frågan man behöver ställa sig när man upprättar en ny källa för referensdata, eller vid första tillfället man behöver komma åt den, är om det verkligen är en acceptabel följd att det kan komma att behöva göras manuella kopior i framtiden. Eller behöver en automatisk koppling sättas upp till den ursprungliga datakällan?
All information har en livscykel vilket tycks vara enkelt att missa när man vill göra en snabbfix eller hjälpsam publicering – man ser inte det systematiska problemet som skapar framtida merjobb.

Fördelen med manuell kopiering är att man i webbsammanhang har full kontroll över hur och när något publiceras, man kan själv blanda informationen med bilder och snygga till det som behövs med lite formatering. Nackdelen är förstås att man gjort en kopia och att informationen förr eller senare behöver uppdateras eller tas bort. Vi har nog alla snubblat över hysteriskt inaktuell information. Som nybliven prenumerant på tidningen MacWorld undrade jag när första numret skulle komma ut, gjorde en googling, valde första träffen och fick se utgivningsdatum för två år gamla nummer. Hittade dessvärre inte ens en länk till aktuell information.
Informationen riskerar att relativt snabbt bli inaktuell eller direkt vilseledande, dessutom uppstår ofta någon sorts ansvars-vakuum mellan ursprunglig ägare av informationen och den som publicerade den på webben.
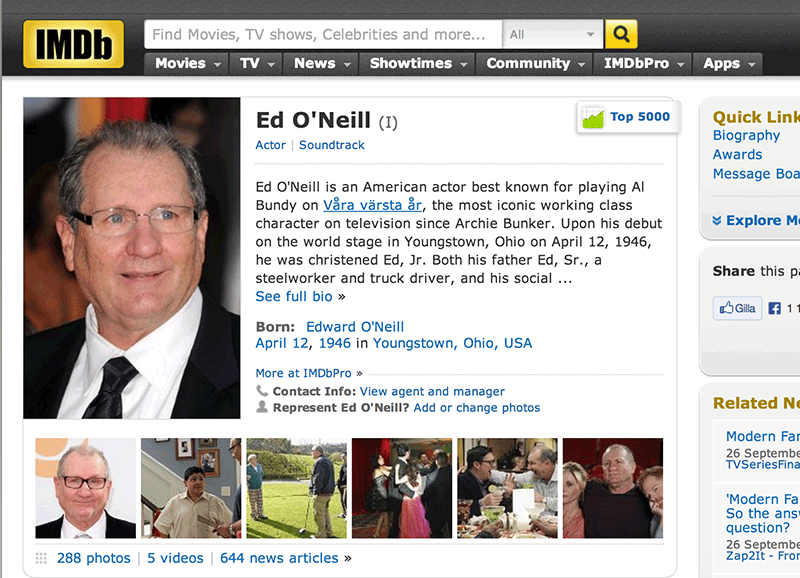
Fördelen med en helautomatisk koppling är att man kan designa informationen att alltid vara aktuell utan löpande insatser. Nackdelen är att det tar mer ansträngning i anspråk. I vissa fall är det avskräckande dyrt, men på sikt kan det ibland vara det enda förnuftiga alternativet. Som på filmtjänsten IMDB där det mitt i engelsk brödtext finns en svensk titel, ”Våra värsta år”, för tv-serien Ed O’Neill är känd för. Genom att IMDB relaterar till sin masterdata är det större chans att jag som svensk förstår vad som pratas om än om det stått ”Married with Children” som råkar vara den engelska titeln.
Det största intranätet jag använt är det Västra Götalandsregionen har. Det ska serva 50 000 medarbetare med information om den väldigt mångfacetterade verksamheten och stötta det dagliga arbetet. Tidigare när ekonomi- och personalavdelningarna fortfarande var decentraliserade fanns det mängder med lokala sidor med information till medarbetarna – information som ofta inte var det minsta unik på en lokal nivå. Löneutbetalningsdagar exempelvis. Det fanns massor med sidor på intranätet som informerade om vilken dag i månaden lönen betalades ut. Hur stor andel av dessa sidor var uppdaterade i början på ett nytt år? Inte så många dessvärre! Känns det som ett meningsfullt jobb för flertalet redaktörer att manuellt hantera flera kopior av information som redan finns i ett annat system? Antagligen inte! Dessutom sänker man förtroendet för intranätet ju mer inaktuell information användarna stöter på.
Har du stött på ett intranät som bara haft aktuell information? Om så är fallet gissar jag att det tillhör undantagen som dessvärre bekräftar regeln att intranät inte får den omsorg de förtjänar.
Motsvarigheten för en publik webbsida kanske kan vara att annonsera ut en produkt som slutat tillverkas och inte återfinns någonstans i leverantörskedjan. Om du beställer en sådan och får meddelandet om att den inte finns tillgänglig kommer nog ditt förtroende för det företaget få sig en törn. Ska man tjäna pengar på sin webbplats så gäller det att förekomma kundernas besvikelser, åtminstone med tanke på hur enkelt det är för kunden att söka upp en konkurrent. Därför finns ofta lagerstatus och förväntad leveranstid med på webbshoppar som en av flera delar för att göra kunden trygg i sitt val.
Intranätets motsvarighet med löneutbetalningsdagar vore kanske att man samlat denna referensinformation i en datakälla, om en sådan inte redan fanns, och erbjöd den till alla som ville ha den. På ett intranät skulle det säkert bli en så kallad widget, en liten ruta som visar de 12 kommande lönedagarna vilket hämtats direkt från lönesystemet.
Frågan man behöver ställa sig är om man har råd med det manuella arbetet, med dess risker, och om det kommer ge ett tillräckligt bra resultat. Troligtvis har man bättre saker att sysselsätta sig med än att hålla reda på alla kopiors aktualitet.
Pratar du med en IT-leverantör, eller din egen IT-avdelning, kommer de säkert ha massor med idéer på lösningar för masterdata-hantering. De kommer säkert nämna termer som Enterprise Service Bus (ESB) för att servera informationen mellan alla system. Det kan vara en god idé om organisationen ändå har anledning att använda sådan teknik, annars är det nog smartare att tänka kring publika API:er, och öppna data, vilket kommer senare i denna bok. Först behöver vi gå igenom konceptet med metadata. Utan metadata är information nästintill helt meningslös, död och oanvändbar.
Vikten av att märka upp information med metadata

Metadata används i nästan alla tänkbara sammanhang. Det kan kategorisera ett dokuments innehåll så användaren vet om det är läsvärt, men det kan också ligga till grund för navigering på en webbplats eller att det blir möjligt att hitta rätt via en sökfunktion.
Många associerar huvudsakligen ordet metadata med ordet nyckelord, som i de ord man använder vid sökningar på sökmotorer. Det är inte fel i sig men metadata är egentligen all information som sammanfattar, beskriver eller kategoriserar annan information. Metadata kan lika gärna vara en geografisk koordinat för var ett foto togs som att det i ord kan klassificera sakinnehållet i en text. Metadata är någon form av beskrivande etikett som följer med det som det försöker beskriva. Se exempelvis en klassisk prislapp. De innehåller inte sällan valuta, en siffra för pris och vilken vara som avses.
Metadata tenderar att fungera som en informationsmängds innehållsförteckning. Utan metadata, och effektiv användning av den, drar man inte nytta av sina informationssystems fördel gentemot trycksaker – nämligen att det kan vara enkelt att hitta även i enorma informationsmängder bara de är välstrukturerade. Om man inte vårdar sin information med genomtänkt metadata är risken stor att informationen inte kommer användas eller bidra till något av värde, primärt för att den blir svår att hitta och det man inte hittar finns inte.
Metadata kan vara synonymer till ord som finns läsbart i informationsmängden, eller mer abstrakta och relaterade koncept för det som beskrivs. Kombinationen av all metadata för en informationsmängd kan vara det som röjer alla tvivel om att man har funnit rätt information redan innan man tagit det av innehållet.
Hur skulle du märka upp löneutbetalningsdagar om du måste upprätta en ny källa i ett MDM-system då koppling till lönesystem inte kan göras? Även i ett MDM-system behövs ordning. Här kommer ett förslag:
- Titel: Löneutbetalningsdagar
- Informationstyp: Referensdata
- Informationsserie: Gemensam referensinfo
- Uppdatering: Löpande
- Ansvarig: Namn Namnsson
- Målgrupp: Alla anställda
- Giltighet: 2016-01-01 till 2016-12-31
- Nyckelord: lön, lönen, 2016,
Är det någon ytterligare punkt ovan som saknas för att det ska gå att undanröja alla tvivel om vad för information som beskrivs och vad man kan förvänta sig händer med den? Det är smart att stämma av dessa idéer med kollegor då man kan se på saken ganska olika. Dessa metadata tillsammans med en lista med de faktiska lönedagarna och det är bara att erbjuda alla andra informationssystem dessa uppgifter som en prenumeration.
Man kan inte vid skapandet av information veta alla sätt som dess konsumenter kommer att försöka finna den. Dock måste man samla in så pass mycket strukturerad metadata så att den kan fungera som ett uteslutande filter. Men också ostrukturerad metadata, som ett antal beskrivande nyckelord, för den som inte riktigt vet hur man finner materialet utan en sökfunktion.
Tänker du låta andra komplettera med metadata till information de inte själva skapat? Eller föreslå alternativa titlar? Det kan vara en bra idé så länge som användarnas bidrag separeras från skaparens innehåll har man inget att frukta. Fördelar med att låta vem som helst bidra är bland annat:
- Den som skapar informationen kanske inte har samma språkbruk som mottagarna. Jämför gärna med byråkrater som Skatteverket, bland allmänheten används ord som moms när byråkraterna kallar det mervärdesskatt. Har man fler av dessa ord blir informationen enklare att hitta i en sökfunktion, eller navigering som baseras på metadata.
- Attityden till informationen kan förändras till det bättre. Innehållet kan bli mer av allas angelägenhet om alla kan bidra, och diskussioner om innehållet blir nog mer konstruktiva.
- Kompetens kommer upp till ytan. Organisationen kan hitta dolda talanger ute i organisationen eller att vissa medarbetare är mer mångsidiga än man trott.
- Innehållet blir mer angeläget att uppdatera. Då det är lätt att finna och troligen har färre konkurrerande kopior.
Ett av målen med att lägga in kollaborativa delar i informationssystem är att åtminstone den viktigaste information blir självorganiserande, på grund av de som har behov av den själva utför jobbet. Men som sagt, det är alltid värt att separera den ursprungliga skaparens syn på metadata och innehåll från mottagarnas bidrag.
Har man riktig tur finns det en fungerande modell för metadata att anamma. En som talar om exakt vilka fält som måste finnas, vilka som måste fyllas i och vilka som är valfria. Tänk om det dessutom gör din metadata-insamling kompatibel med andra datakällor. Hörde jag ett amen?
Metadata-specifikationer gör dina data mer standardiserat
Du stöter på metadata-standarder dagligen men det är inte säkert att du är medveten om det. Tänk på det som strukturerad data där du lite granna skrivs på näsan vad information är. Ofta med etiketter, ett kolon och sedan själva innehållet. Som på insidan av en bok exempelvis.
Ordlista – Metadata-specifikation alternativt strukturell metadata:
För att de metadata som samlas in ska vara kompatibel med andra datakällor följer man ofta en metadata-specifikation, en standard. Exempel på en sådan är Dublin Core (DC). Detta anger vilken struktur insamlad metadata ska ha och vilka värden som ska anges.
Skrivna verk gav en explosion av information för sin tid, redan långt innan boktryckarkonsten. Biblioteket i Alexandria var en av de första platserna för att centralisera kunskap. Egyptierna hade som mål att ha en egen kopia av varje skrivet verk som passerade Egyptens gränser. All kunskap ansågs vara viktig och värd att spara en kopia av. Hur i hela helsefyr skulle man kunna beskriva vilken bok man menade, logiskt ordna dessa i hyllor och i akademiska texter relatera till enskilda verk?
Här hjälper standardiserad metadata till. Data som relaterar till det publicerade verket, helt enkelt. Titta noggrant någon sida in i en tryckt bok ska du se att det finns en sida som informerar om boken. Ofta finner du:
- Titeln på boken.
- Vem som skrivit den, och vilka som eventuellt bidragit.
- Vilken utgåva du håller i handen.
- När den trycktes.
- ISBN-nummer så du kan identifiera boken och beställa fler.
- Vem som publicerat boken och vem som äger upphovsrätten.
Här började man standardisera vilken data om ett verk som kunde behöva samlas inledningsvis i en bok. Fördelen med en metadata-standard är att man vet att samma typ av information beskriver samma sak och att man har samma syfte med sin datainsamling.
Dublin Core (DC) är nog en standard som är mest känd i bok- och biblioteksvärlden. Den förenklade versionen av DC innehåller femton värden för att beskriva ett verk, nämligen:
- Titel (Title).
- Skapare (Creator).
- Ämne (Subject).
- Beskrivning (Description).
- Publicist (Publisher).
- Bidragande (Contributor).
- Datum (Date).
- Typ (Type).
- Format (Format).
- Identifierare (Identifier).
- Källa (Source).
- Språk (Language).
- Relation till annat (Relation).
- Täckning (Coverage).
- Rättigheter (Rights).
Läser du den bakomliggande HTML-koden för en webbsida kan du ibland se koder som den nedan där DC använts för att beskriva sidan:
<meta name="DC.Publisher" content="Marcus Österberg" />
Poängen med att följa en metadata-standard är att den information du märker upp enligt en standard blir kompatibel, jämförbar alltså, med andras information som följer samma standard. I detta ligger en dold problematik, nämligen att det gäller att använda samma standard som de du vill jämföra dig med. Det låter kanske enkelt i teorin, men i många fall används massor med lokala varianter på vilken information som samlas in. Oavsett om omvärlden väljer att följa en standard är det bra för ens egen skull att använda en med tanke på att man inte riktigt vet vad som kommer hända under informations livslängd.
Det är bra om den som matar in informationen är medveten om att den ska följa en viss standard, eller får hjälp att följa den via ett systemstöd så det blir något sånär konsekvent använt.
Pratar du om standarder med IT-leverantörer tenderar de till att påstå att de följer alla möjliga standarder. Det gäller att försöka se igenom säljsnacket och lista ut om de menar att systemet följer en de facto-standard, sin egen systemstandard alltså, som binder dig till deras produkt eller om det är en öppen standard man pratar om. Standarder ska väljas med omsorg genom att försöka lista ut vilken som är mest etablerad och stödjer de behov man kommer att ha.
För webben finns det tack och lov bra öppna standarder för metadata i form av vanliga metadata-taggar i HTML som följer bland annat Dublin Core, och även mikrodata vilket vi kommer gå in på lite senare.
Nu en titt på två varianter på hur stor frihet man ger användarna i val av ord. Först det ordningsamma sättet med kontrollerade vokabulär, sedan folksonomi som styrs av användarnas egenvalda språkbruk.
Kontrollerade vokabulär
Ordlista – Kontrollerat vokabulär:
En lista med noggrant utvalda ord inom ett visst ämne. De används ofta som metadata för att kategorisera annan information. Inte sällan finns även ett ords synonymer med i en vokabulär och ibland är orden sorterade i en trädstruktur med interna relationer. Ofta avses samma sak när man istället säger ord som koder, kodverk, klassificering och terminologi.
Ordlista – Ontologi:
En uppsättning med kunskap inom ett visst område. Sätter upp relationer mellan flera vokabulärer och taxonomier.
Ett kontrollerat vokabulär är en fördefinierad lista med omsorgsfullt utvalda ord som godkänts för användning inom en bransch, inom en organisation eller kanske är tvingande för att vara kompatibel med en viss metadata-standard. De används för att klassificera information på ett gemensamt och konsekvent sätt som står sig över tid och överbryggar gränser.
Anledningen till att dessa vokabulärer tas fram, och underhålls, är för att uppmuntra till användning av ett gemensamt språkbruk, där precision i ords betydelse är av största vikt för att undvika missförstånd och tvetydigheter. Med andra ord behövs samarbete och bred uppslutning för att en vokabulär ska bli riktigt användbart.
Du kanske frågar dig om det ens kan uppstå tvetydigheter? Ta ordet cancer som ett exempel. Om du hittar det som ett kategoriserande nyckelord på en webbplats, är det då givet vad det är som avses? Ibland är det lätt att tro att något inte är tvetydigt, men säg den lycka som består då det allt för ofta beror på brist på insikt.
På rak arm kan jag tänka mig att ordet cancer kan handla om:
- Namnet på en grupp sjukdomar?
- En stjärnkonstellation?
- Ett stjärntecken som indikerar ungefärlig tidpunkt på året för födsel enligt pseudovetenskapen astrologi?
- En av figurerna i Transformers?
Du kanske kan komma på flera varianter? Sen är det säkert vanligare att man menar sjukdomen framför figuren ur Transformers – hur nu exempelvis en sökmotor ska lyckas gissa sig till det.
Om man inte blir upplyst om hur metadatamärkningen är gjord kan man inte ens veta vilket språk som använts.
Om du får en lista med all information uppmärkt med nyckelordet cancer – hur vet du då att all information avser samma sak? Det gör du nog inte om det inte tydligt framgår att man aktivt jobbar med vokabulär och entydighet.
Angående att skilja på metadata som tillhör en vokabulär eller inte har videotjänsten Youtube ett exempel på hur man kan göra. Skriver man in en tagg, nyckelord alltså, som råkar finnas i en vokabulär så meddelas man det genom en beskrivning inom parentes där man kan se vilket typ av data Youtube anser nyckelordet tillhör, exempelvis ”City/Town/Village” för inmatade städer. En smidig lösning för att se till att användaren är införstådd i att denne just matade in information som kan struktureras till något entydigt – om nu användaren avsåg träffen ur vokabuläret – annars står det användaren fritt att lägga in det som ett vanligt nyckelord.
Exempel på vokabulär är ICD-10 som är ett internationellt sätt att klassificera sjukdomar och hälsoproblem. Samverkansforumet för denna vokabulär är Världshälsoorganisationen (WHO) som lyder under FN. ICD-10 innehåller över tiotusen sätt att beskriva medicinska diagnoser på ett flertal detaljnivåer. Då termerna och dess innebörd har översatts till många språk överbryggar dessa klassificeringar språkliga barriärer.

Vokabulär är ibland specialiserade på vissa användningsområden. För att bygga vidare på det medicinska exemplet så finns en uppsjö andra vokabulär, som MeSH – för ämneskategorisering av medicinsk information – och HL7 som beskriver relaterad information som laboratorieresultat. Som du säkert förstår behöver flera av dessa vokabulärer användas samtidigt inom en organisation då inget vokabulär är allomfattande och de har ofta olika styrkor.
Folksonomi
Ordlista – Folksonomi:
Vokabulär, ordlista alltså, utan central styrning eller standardisering. Kallas ibland för demokratisk, social eller kollaborativ taggning.
En folksonomi är en lista med ord och begrepp som inte är standardiserat eller centralt styrd av någon organisation. Det som karaktäriserar en folksonomi är att de ord som folk väljer att använda lyfts fram som en ordlista. En folksonomi kan stå i tydlig kontrast med avsnittet tidigare om kontrollerade vokabulär. En högst social och demokratisk syn på vilka ord som kan vara nyckelord. Nya ord, slangord, vanligt folks sätt att uttrycka sig i ett kreativt kaos som uppdateras frekvent i en folksonomi. Kontrollerade vokabulär ges ofta ut i en ny version varje år, och för trendiga ord kan det dröja väl länge om det nu ens finns avsikt att ha med sådant.
2012 års mest tjatade trend var allt som hade med musikvideon ”gangnam style” att göra och stor kreativitet uppstod när folk gjorde egna tolkningar av dansen. Behovet av att använda nyckelordet ”gangnam style” kunde förstås inte vänta på någon kommittés beslut om inkludering vilket talar för behovet av en folksonomi framför ett kontrollerat vokabulär.
Fungerar arbetet med metadata om man har begränsad uttrycksfrihet med en ordlista, vill man ha fullständiga friheter, eller ett kontrollerat mellanting med både folksonomi och kontrollerat vokabulär? Det är värt att fundera igenom när man designar ett informationssystem om verkligheten är så enkel som man först tänker sig. Ett alternativt sätt att lägga upp detta är att skilja ut de system som kan hantera ett kaos och i vilka fall det skulle påverka negativt.
Seth Earley, en av auktoriteterna inom området informationsarkitektur, menar att måttstocken för kontrollbehovet hänger ihop med om innehållet:
- Kommer att återanvändas frekvent i andra sammanhang.
- Redan ingår i en kontrollerad process.
- Besvarar frågeställningar någon kan ha, är kanske godkända metoder eller riktlinjer, eller jämförelseinformation.
- Informationen har en betydande kostnad att ta fram.
Exempel på typiska system som antagligen behöver kontrollerade vokabulär är diariesystem, dokumenthantering, digital resurshantering och processystem. Motpolen är de system som ofta klarar sig gott på enbart folksonomi, och de har följande egenskaper:
- Ingår i en kreativ eller kaotisk process.
- Tenderar till att vara problemlösning på ett praktiskt sätt.
- Har hög grad av samarbete mellan olika individer.
- Informationen uppstår oavsett om den är efterfrågad eller inte, som i diskussionsforum eller mikrobloggar.
Exempel på system som rimligen klarar sig med en folksonomi är; bloggar, snabbmeddelanden och chatt, wiki och andra samarbetsplattformar.
Det är inte ovanligt att folk har en medfödd känsla för vilken av dessa varianter man bör ägna sig åt, oavsett vad behovet nu än må vara. En av mina metadata-intresserade kollegor som jobbar med dokumenthantering inom vården fällde en, för mig, fascinerande kommentar nedan något parafraserad:
”Eeeh. Vem är det som har bestämt vilka hashtaggar ni twittrare får lov att använda?”
– en kollega
Nu är det givetvis så att på mikrobloggar som Twitter kan man hitta på helt egna nyckelord att använda som hashtaggar (länkarna med brädgård framför sig). Det är själva tjusningen med ett ostyrt media som Twitter att man över kvällen kan ha en gemensam hashtagg att diskutera kring utan någon utomståendes gillande eller godkännande på förhand.
Du kanske undrar var på kontrollskalan webbpubliceringssystemen hamnar? Får man hitta på sina egna ord eller ska man utgå från vokabulär? Jag tror att de flesta behöver en kombination av båda, men viktigast är att få hjälp med ordval oavsett om ordet ligger i vokabulär eller redan finns i ens folksonomi. Det främjar återanvändning av ord inom folksonomin, hjälper till med stavning och minskar mängden snarlika nyckelord.
Arkitektur med hjälp av API:er och öppna data
Ordlista – API (Application Programming Interface):
En anslutningspunkt för att lämna ut information från ett system. Ibland erbjuds vissa av systemets funktioner till andra system via ett API. Ofta är det via API:er mobilappar, webbplatser och andra funktioner hämtar sitt innehåll och kommunicerar tillbaka. Ett publikt API är ett API man erbjuder andra att använda.
Ordlista – publikt API:
Ett API som uppmuntrar externa parter till användning. Ett publikt API ska vara dokumenterat, ha supportinformation och ha någon form av utfästelse från utfärdaren om att man avser hålla det levande för externa användare.
Ordlista – PSI-lagen:
Lag baserad på ett EU-direktiv som reglerar på vilket sätt statlig verksamhet måste dela med sig av insamlad information.
Ordlista – Öppna data:
Filosofi som strävar efter att man delar med sig av sin information. Allra minst erbjuda en fri användning men gärna på ett strukturerat sätt andra kan designa tjänster med.
Ofta ligger värdefull information i ett system som inte lätt kan prata med andra system. Här kommer behovet av integration fram för att samarbeta om information mellan system, över plattformar eller kanske rent utav att erbjuda som en produkt på en öppen marknad.
API:er är, som smörjmedlet mellan kuggarna i en växellåda, det som får webben, och alla mobila tjänster, att fungera tillsammans med alla system de är beroende av.
Det finns åtminstone två ingångar till detta med API:er. Dels hur man kommer åt information i ett potentiellt svingammalt, eller åtminstone redan etablerat system, men också hur du kravställer nya system – oavsett om de byggs på beställning eller köps in.
Publika API:er, öppna data och PSI-lagen
Att idag inte beakta öppna data, eller åtminstone ett publikt API, när man bygger ett informationssystem bör ses som ett tjänstefel som förtjänar en reprimand. Som företag är en öppenhet med sina data i många fall en naturlig del av digital affärsutveckling. För skattefinansierade verksamheter finns mängder med datakällor som skulle göra nytta ute i samhället bara genom att de öppnats och då generera nya skattekronor. Bland annat kan medborgarna själva korrigera och förbättra innehållet, så kallad crowdsourcing, eller tipsa om tillfälliga undantag. Det är på gränsen till oetiskt om en statlig aktör inte delar med sig av de datakällor de har om den datakällan kan generera nytta ute i samhället – det svåra för staten är att veta vad som är intressant att öppna upp och hur. Utvecklare som bygger tjänster behöver oftast någon annans data för att inte göra onödig datainsamling. Det kan vara växelkurser, väderprognosen för en viss plats, recensioner av matställen med mera. Det är en naturlig del av utveckling idag att kolla om det finns öppen data man kan dra nytta av när man bygger nytt. Istället för att fixa till en strulig funktion på webbplatsen kanske den helt kan ersättas med ett externt API?
Stor del av organisationers och företags interna verksamhet går ut på att hantera information. Att låta flera samarbeta kring samma information gör datakällan mer trovärdig och välkänd vilket gynnar även den som kunde valt att hålla den intern inom organisationen. Företag kan tjäna pengar på detta och de skattefinansierade kan spara pengar – så inte fler än nödvändigt samlar in samma information. Tänk dig själv hur många olika typer av verksamheter på webben som exempelvis skulle ha nytta av att statens samlade tillgänglighetsinformation släpptes fri. Helt plötsligt skulle alla som guidar till en fysisk plats kunna ha information om hur tillgänglig platsen är för rörelsehindrade, blinda, vilket språkkunnande personalen har med mera. Staten har massor med bra data inom alla möjliga områden.
Andra exempel som ofta hålls fram för att sälja in öppenheten till sin information är där man försöker ta hjälp av folk i någon tävlingsform. Exemplet jag själv hört återberättas stämningsfullt många gånger är det om företaget Goldcorp som utlyste en tävling om vem som med deras geologiska data kunde hitta det guld de själva hade svårt att finna för att höja lönsamheten i en befintlig gruva. I potten fanns 575 000 kanadensiska dollar i priser till de som deltog i denna digitala guldrusch. Satsningen möjliggjordes av Goldcorps VD, Rob McEwen, som enligt uppgift tagit inspiration av den tidiga samarbetskulturen på internet under 1990-talet.
De som kom först i denna tävling var inte geologer, de utförde jobbet utan att behöva resa till andra sidan klotet, de löste problemet från Australien. Resultatet av dessa 575 000 kanadensiska dollar blev cirka 2 år tidigare start av gruvans produktion och värdet på utvunnet guld via dessa fynd landar på flera miljarder kanadensiska dollar.
Exemplet med Goldcorp är förstås ovanligt spektakulärt i sin storhet, men det är ett exempel på att andra kan hjälpa dig med dina problem om de har tillgång till dina data. I vissa fall kanske de gör det gratis för att de och din verksamhet delar ett mål dina data kan realisera.
Modeordet mashup blev väldigt omtalat runt 2006 och innebär att kunna kombinera flera datakällor till en tjänst. Att ta två eller fler datakällor och göra något som är bättre än delarna. Numera pratas det inte så mycket om mashups då det är en naturlig del i konceptutvecklingen för nya tjänster, men behovet av åtkomst till datakällor är allt större. Vanligast är nog att man kombinerar sin egen datakälla med någon annans.

Tar du bilder med Instagram-appen i din mobil kan du välja ut en namngiven geografisk plats att associera bilden med hos Instagram. Instagram använder då ett API gentemot geodata-tjänsten Foursquare och slipper på så sätt själva vara aktiva kring allt som har med geodata att göra. Dessa två organisationer har säkert en affärsuppgörelse om hur de valt att samarbeta även om Foursquare erbjuder vem som helst att ansluta till deras API.
Nästa del tar upp vad inom öppenheten som är viktigt när man bygger informationstjänster, vilket inte bara är av intresse för den offentliga sektorn. Alla kan dra nytta av sina rättigheter att få data från staten.
Bakgrund till PSI-lagen
Sommaren 2010 tillkom en lag som populärt kallas för PSI-lagen (PSI, Public Sector Information), men kanske tydligare med sitt fullständiga namn ”lagen (2010:566) om vidareutnyttjande av handlingar från den offentliga förvaltningen”.
Lagen avser att förbättra möjligheterna för medborgare att få insyn och delaktighet i staten. En tänkt bieffekt är att innovation och tillväxt ska uppstå i näringslivet med den information som staten samlat in. Lagen kom från EU:s PSI-direktiv och innebar ett stort steg framåt för många europeiska länder, dock inte i Sverige då lagen i ganska liten utsträckning utökade vad offentlighetsprincipen redan erbjöd. Detta har nog fört med sig att det inte blev någon väckarklocka inom statlig verksamhet utan många lutar sig tillbaka och menar att man redan uppfyller lagens krav. Den stora skillnaden består i att man i Sverige sedan länge kunnat kräva ut papperskopior på stor del av statsförvaltningens information. När PSI-direktivet inte krävde digitala kopior uteblev chocken i Sverige medan man i flera andra länder tog det digitala steget direkt från att tidigare inte behövt lämna ut några handlingar alls.
Att åtminstone de datakällor som det finns ett allmänintresse av bör vara öppna kan kännas som en självklarhet då de är finansierade med skattemedel. Trots detta finns det begränsningar som kan sökas för tre år i taget om man tillhandahåller en tjänst som är av allmänintresse. Många utvecklare skulle nog påstå att det handlar om statens egenintresse då Lantmäteriet, Bolagsverket och Statistiska Centralbyrån med flera har informationsförsörjning som verksamhetsidé. De råkar också sitta på några av de mest intressanta datakällorna som utan tvekan har ett allmänintresse.
En vän jag inte tänker namnge jobbade på SMHI i brytpunkten när myndigheten gick från att hålla på sina data till att dela med sig. Denna vän råkar vara mycket kompetent på det mesta som rör IT och fick spel när några av hans kollegor hade lagt en massa tid på att göra en undermålig visualisering av de data de fram till nyligen inte delat med sig av till externa parter. Han mumlade något om att högstadieelever skulle göra ett bättre jobb på kortare tid om SMHI bara släppte sina datakällor.
Att som statlig aktör öppna sina datakällor spetsar till diskussionen om vad ens huvudverksamhet egentligen är. Självklart ska inte staten sluta prioritera informationsförsörjning till samhället bara för att man släpper ut sina data, men att lägga tid på att paketera bonus-information blir säkert mer avlägset, som min vän noterade, då många andra är duktigare på det.
Problemen med PSI-lagen handlar om tillgången till data
När jag mött entreprenörer som försöker använda sig av denna lag för sina affärsidéer får de ett lakoniskt uttryck i ansiktet och pratar om “staten är ett pappers-API” och att “vi behöver fler jurister än utvecklare i vårt företag”.
PSI-lagen hade behövt något som åtminstone reglerade i vilket skick informationen lämnas ut. Papper borde enbart accepteras om informationen inte finns i annat än pappersformat inom den tillfrågade organisationen. Utvecklare håller oftast tillgodo med strukturerade format som textfiler, databasexporter, Excel och liknande som praktiskt taget alltid går att få ut från befintliga system.
Det pågår konstant ett arbete inom EU, synliggjort av EU-kommissionären Neelie Kroes bland annat via Twitter på @NeelieKroesEU, som strävar efter att förtydliga kraven på att lämna ut information i ett strukturerat elektroniskt format. Hur det går återstår att se men min gissning och förhoppning är att det blir mer krav på strukturerad digital utlämning för varje iteration av lagstiftningen.
Vad är då öppna data?
Öppna data är digital information som inte har begränsningar avseende återanvändning, till skillnad från PSI-data som tillåter begränsningar i återanvändning. Öppna data ska alltså vara befriat från bland annat upphovsrätt, patent och andra hinder. När staten är utgivare av sådan information brukar det kallas för öppna offentliga data.
Open Government Working Group har gjort ett av flera försök att enas om vad som kan anses vara öppna data. Dessa krav, hämtade från Wikipedia, stämmer åtminstone med min uppfattning:
- Komplett: Information som inte innehåller personuppgifter eller lyder under sekretess görs tillgänglig i så stor omfattning som möjligt. Detta gäller särskilt databaser med material som skulle kunna vidareförädlas.
- Primär: Information skall så långt det är möjligt tillhandahållas i originalformatet. Bild- och videomaterial skall tillhandahållas i högsta möjliga upplösning för att möjliggöra vidareförädling.
- Aktuell: Information skall tillgängliggöras så snabbt som möjligt så att värdet av den inte försvinner. Det bör finnas mekanismer för att automatiskt kunna få information om uppdateringar.
- Tillgänglig: Information görs tillgänglig för så många användare som möjligt för så många ändamål som möjligt.
- Maskinläsbar: Informationen är strukturerad på ett sätt som möjliggör maskinell bearbetning och samkörning med andra register.
- Fri: Informationen är tillgänglig för alla utan krav på betalning, eller inskränkningar i form av licensvillkor och registreringsförfaranden.
- I ett öppet format: Det format informationen lämnas i följer en öppen standard, alternativt är dokumentationen till formatet fritt tillgänglig och fri från patent eller licensvillkor.
- Utan licens: Datakällan i sig ska vara fri från licenskrav eller andra saker som kan begränsa möjligheten till återanvändning.
Vissa punkter är mer öppna för tolkning än andra. Kanske främst punkt 7 som kan vara allt från en banal textfil till ett avancerat API för spridning och synkronisering av information.
Om man kombinerar öppna data med ett så kallat API, vilket många anser är en självklar kombination, uppstår möjligheten för andra att direkt bygga tjänster på den information som samlats in. Det är egentligen inte ett krav på öppna data att den erbjuds via ett publikt API, men om du vill uppmuntra till användning är det värt att kolla under vilka förutsättningar utvecklare vill ta del av din info. Utlämningen av data behöver vara pålitlig, smidig och väcka utvecklares förtroende om de ska våga använda det. Utvecklare kanske inte alltid prioriterar att tjäna pengar på det de bygger men snabbt lär de sig att undvika frustrationen som uppstår med till synes onödiga hinder, villkor och annat strul.
Nyttan med ett API för en nystartad verksamhet eller vid nybyggnation
Det är möjligen inte uppenbart vid en första anblick, men affärsmodellen för API:er är att inte alla ska behöva uppfinna hjulet själva. Dagens informationssystem är så komplexa att ta fram att den hjälp man kan få av andra tacksamt tas emot. Att som startup slippa göra allt man inte är bra på är idag en förutsättning för att inte garanterat misslyckas och nu är man i många fall beroende av att leta bland publika API:er för det någon annan kan göra bättre. Listan kan göras mycket lång med information och tjänster man är beroende av för att vara effektiv. Saker som aktuell växelkurs för internationella bolag, geografisk data som från Instagram/Foursquare-exemplet, aktuellt väder för en plats eller stödfunktioner för att minska mängden spam-kommentarer på ens blogg med mycket mer är något någon annan troligen gör bättre än du och redan erbjuder ett API för.

Jag tänkte att en liten lista kanske är på sin plats, listan om varför en startup, eller en ny webbtjänst, kan dra nytta av att låta ett eget publikt API spela huvudrollen i tjänsten.
1. Det är normal affärsutveckling
I dagens uppkopplade samhälle där du inte vet var din information hamnar i slutändan är det svårt att klara sig utan ett API. För de egna behoven ska det inte komma som en chock att ett API hjälper till när din webb, intranät, mobilapp och alla andra system vill ha tillgång till snarlik information. När ett samarbete med annat företag kommer på tal är det åtminstone delvis redan färdigt för integration över organisationsgränserna.
Är det något problem många ställs inför som du kan lösa med hjälp av en dator? Med ett API kan du erbjuda hela världen din tjänst utan att behöva varken klippa dig eller flytta från Hallsberg 🙂
API:er är dagens informationsdisk, automatiserade sekreterare och personal i en och samma paketering. Tänk också på att ett API inte automatiskt är privat bara för att det inte är publikt. Har du ett API till en mobilapp kan andra också använda det och ett publikt API är en bättre start på en relation med andra utvecklare än att de i desperation använder det dolda API:et.
2. Bygger relationer kring din tjänst
Se det som ett ekosystem där din tjänst från dag ett är mittpunkten. Det må till en början vara få som bryr sig men för varje ny återanvändare har du någon vars lycka delvis hänger ihop med din – gissa om ni har något att prata om. Externa utvecklare bidrar med nya vinklar, innovation och expertis till något alla deltagare har nytta av.
Tänk om någon av de som använder ditt API lyckas stort. Det kommer till viss del spilla över på din tjänst och det kan ge oväntade affärsmöjligheter.
3. Tillgängliggör data och bidrar till transparens
Det är nog många som önskar att deras arbetsgivares datakällor var mer tillgängliga för den egna personalen. Jag är absolut en av dem med behov av mer insyn i vad min arbetsgivare har för data, där kommer begreppet data discovery in – hur lätt det är att utforska organisationens digitala informationsresurser. Den interna uppfinningsrikedomen kring befintliga datakällor hämmas ofta helt i onödan av att kreativa personer inte har tillgång till data de faktiskt behöver för att göra sitt jobb på ett bättre eller effektivare sätt.
Även med ett API blir det en silo av information, skillnaden är att man vet vilka som finns, vilken silo man kan ha nytta av och vid behov kan man med viss möda använda innehållet. Någon har lagt ansträngning på att samla ihop information, då är det en god idé att dra nytta av det.
4. Investerare tar detta nästan för givet
Hur stort tror du Twitter varit idag om de aldrig erbjudit användarnas data till tredje part? På grund av detta fanns en uppsjö av klientprogram för alla tänkbara plattformar vilket bidrog till Twitters popularitet. Andra utvecklare drog en massa erfarenheter Twitter senare kunde använda sig av själva och kapitalisera på.
En stor del av att lyckas på nätet är att ta hjälp av andra och göra mesta möjliga så snabbt som det bara går, ett API är ofta en del av den strategin.
5. Gör bra mashups
Google Maps är ett gigantiskt exempel på mashup många använder sig av. Ett exempel på där de som använder Googles kartor på sina egna webbplatser dels etablerar Google som kartaktör men samtidigt om tjänsten blir populär kommer behöva börja betala för sin användning till Google.
Kombinationsmöjligheterna med mashups är större än man kan tro med alla nischintressen som frodas på webben, tillsammans med alla tjänster som hjälper till med funktioner som video med mera som är svårt att lösa själv.
6. Självgående innehållsmarknadsföring
Spritvarumärket Absolut gjorde en intressant marknadsföring på temat under 2013 när de bjöd in till innovationstävling kring deras nya API. API:et innehöll mängder med ingredienser för drinkar där Absoluts egen vodka inte direkt av en slump råkade vara en ingrediens.
Blir API:et populärt eller drinkrecepten används på någon annans webbplats får Absolut den där värdefulla trovärdigheten av någon som verkar vara oberoende. Till all text i recepten erbjöd man i god reklamanda professionellt tagna fotografier och videoklipp fritt att använda via deras API så vidareanvändare och utvecklare inte behövde tänka länge kring kvaliteten på innehållet.
Designa ett publikt API med utvecklarna i fokus
Det är en god idé att börja alla IT-projekt med planering av vilken data som kommer hanteras, efter det har man en plan för konstruktion av ett API för ens egna behov. Detta API är det lämpligt att man själv använder – eat your own dog food – på samma vis som om man vore en extern part. Om du inte vågar använda ditt egna API kan man fråga sig varför någon annan borde vara mer våghalsig än du?
Precis som man sedan många år skiljer på innehåll och design inom webbutveckling, genom att använda stilmallar och designbefriad HTML, på samma sätt ska man skilja på data och presentation genom att använda ett API för det data webbplatsen hanterar. Står man inför ett starta upp ett nytt webbprojekt börjar man med att titta på vilken data man redan har, vad man behöver, på vilket sätt man ska samla den och vilka delar som är meningsfullt att dela ut publikt.
Släpper man ett publikt API finns några grundläggande grejer som man verkligen bör göra allt för att leva upp till. Även fast man kanske enbart indirekt tjänar pengar på sitt API så liknar förhållandet mellan dig som utgivare av ett API och dina vidareutnyttjare en form av affärsrelation.
Vänligt sinnade användarvillkor och fri licens
Om du vill att någon ska använda ert API är det precis som med allt annat – det kräver god kommunikation och ömsesidighet mellan alla inblandade. Undvik att vara för byråkratisk eller juridisk i utformningen av villkoren. Försök istället att uppmuntra till användning och inspirera till vad man kan göra med den.
I E-delegationens skrivelse ”Vägledning för återanvändning av information” poängteras det att man ska undvika betungande villkor och att erbjuda så fria licensvillkor som det är möjligt. Denna vägledning vänder sig visserligen till offentliga sektorn men samma tankegångar är dock nyttiga även i företagssammanhang. Var vaksam för om något i villkoren är onödigt hårt, eller kanske indikerar att öppenheten är motvillig.
Ett exempel på motvillighet, dock inte inom öppna data, har jag mött av den tidigare monopolisten inom evenemangsbiljetter i Sverige. Jag drev då norra Europas största evenemangswebbplats och frågade om jag kunde få lov att använda det API de själva använde för att slussa mina besökare till rätt del av deras webbplats för att köpa biljetter. Det blev en lite underlig diskussion när de ville ha betalt av mig för att jag skulle lämna över presumtiva kunder till dem. Där satt jag med hundratusentals besökare som läste om enskilda konserter och festivaler men kunde inte vägleda dem till var de kunde köpa biljetterna. Det hade varit mer rimligt att de frågade hur mycket jag ville ha betalt för detta, eller svarade att de inte kunde av något tekniskt skäl. Behöver jag nämna att det finns några fler bolag på den här marknaden nu och att det minsann finns ett antal API:er att välja på.
I de fall det är möjligt bör man använda standardiserade användningsvillkor och licenser, vilket finns ett flertal av, bland annat Open Database License (ODbl) och Creative Commons (CC). Försök dock hitta en standardiserad licens verksamheter som liknar din använder så underlättar det för de utvecklare som då kan samköra dina data med liknande data utan att behöva lusläsa konflikter mellan licenserna. Det är värt att tänka på att de flesta som man vänder sig till med ett API är bättre på teknik än juridik.
Det som bör besvaras av användningsvillkoren är åtminstone följande:
- Eventuell betalningsmodell. Hur många anrop till tjänsten är gratis och exakt hur fungerar det?
- Vilken grundlicens som gäller för informationen. Om undantag från den generella licensen finns, vilken licens gäller då och hur ser dessa undantag ut?
- Om information inte är fullkomligt fri – hur får den då mellanlagras? Det är en fördel om villkoren i klarspråk kan tala om hur länge en vidareutnyttjare av prestandaskäl, eller annat, kan behålla nedladdad data i sitt system.
- Finns en eller flera användningskvoter? Oftast finns ett begränsat antal förfrågningar som kan göras mot ett API och detta är mycket viktigt att få reda på som användare tidigt för att hushålla med resurserna.
Överraska inte utvecklarna med oförutsedda ändringar
Det är lätt hänt att tro att man tänkt på allt, men tro det eller ej så kommer nästan varje framgångsrikt tekniskt projekt att behöva framtida justeringar. När det gäller API:er är det viktigt att planera för detta redan från början genom att designa för framtida tillägg. Det innebär att man ska versionshantera sitt API oavsett om man tänkt sig kommande versioner.
Många gör så att versionsnumret står i adresserna, exempelvis /v1/ eller /version-1/, som används för förfrågningar till API:et. Det gör det lätt att se i koden för projekt som använder API:et vilken version som används. Dessutom behöver man inte oroa sig för krockar mellan adresser i de olika versionerna då de alltid är unika inom sitt versionsnummer. Att ha versionsnumret i adressen är praxis bland de större API:erna, kanske för att det andra alternativet, att lägga versionsnumret i HTTP-headern, är så pass dold att många utvecklare inte vet om att möjligheten ens finns.
Dokumentationen måste förstås även den versionshanteras så dokumentation finns kvar för de som inte kör den senaste versionen av API:et. Det är lämpligt att det finns information om vad som skiljer de olika versionerna åt dels ur ett tekniskt perspektiv men också åt vilket håll API:et utvecklats konceptmässigt.
I praktiken måste det gå att använda en äldre version av ett API under en övergångsperiod om man har andra som använder ens API. Det tillhör god sed att man kontaktar dem med information om förändringarna och hur länge de kommer kunna stanna kvar på den äldre versionen. Egentligen behöver man kanske inte alltid stänga äldre versioner men det är bra att vara öppen med sin ambition kring att ge support på äldre version än den senaste. Som absolut minsta tänkbara avvecklingstid är att ge vidareanvändare av ett API åtminstone 3 månader på sig att avveckla sina beroenden, men även det kan ge upphov till upprörda känslor beroende på vad man satt för förväntan.
På grund av framtida förändringsbehov, och för att lära känna API-användarna, kan det vara en god idé att kräva eller erbjuda registrering, åtminstone av de som är kontinuerliga användare eller använder API:et i affärsliknande syfte. Nyttan för dem är att kunna få information om förbättringar, nya versioner men också ett sätt att kunna komma i kontakt för supportfrågor.
Eftersom API-användningen för en enskild användare kan variera mellan olika dagar är det en fin gest att erbjuda en mjuk kvot med förvarning innan den hårda kvoten slår till och åtkomsten stängs. Det kan exempelvis vara att det skickas ut ett mejl när 75 % av den dagliga kvoten förbrukats. Snyggast är förstås att ens API-användare själv kan välja när denna varning sker. Ska du köpa ett färdigt verktyg för att erbjuda API:er i större skala är detta definitivt något du bör kräva av leverantören.
Försök så långt det går sätta dig in i återanvändarens situation så ska det nog gå bra.
Erbjud data i förväntade format och i lämpliga paketeringar
Det finns två motstående principer vid datautlämning som du behöver förhålla dig till, nämligen att erbjuda data förädlat nog för direkt användning i andras applikationer eller att lämna ut data i sitt ursprungliga format. För att exemplifiera kan den förädlade versionen vara att ett API svarar med sant eller falskt för om en viss stadsbuss är i tid eller inte. Det mer ursprungliga formatet skulle vara att lämna ut all data om alla stadsbussar likt en databaskopia.
Förädlade data är förstås smidigt men samtidigt begränsar det vad man kan göra med informationen. Att få en databaskopia är jättebra för den som behöver göra något annat än det mest uppenbara men samtidigt blir datasetets aktualitet omgående lidande. Ska man själv använda sitt API är det lite lättare att veta hur första versionen kan se ut, men om andra ska få åtkomst bör man omgående ha dessa som bollplank för hur information ska levereras för att gå att använda till något meningsfullt. Risken är att man i all välmening paketerar data på ett sätt som omöjliggör för många att dra nytta av ens API. Exempel på detta jag själv sett är att man konverterar information till läsbara format som Word-dokument när det egentligen bara leder till att återanvändaren får konvertera det tillbaka till ren text.
Om det är möjligt så är en bra start att erbjuda det ursprungliga formatet i lagom stora paket och att det finns sätt att hålla koll på data som uppdateras löpande. För att fortsätta på exemplet med stadsbussar kanske det blir att paketeringen är att hämta all info om en viss busslinjes planerade tidtabell, sedan kompletteras detta med en simpel API-tjänst som anger hur verkligheten förhåller sig till tidtabellen.
Vilket (dokument)format är bäst? Ja, det beror på vem du frågar. Frågar du en normalteknisk person tänker de nog på hur man ska kunna öppna informationen på den typ av dator de är bekanta med. Svaret blir säkert något som är bekant för de flesta, kanske något från Office-paketet, Adobes Creative Suite, PDF eller liknande. Frågar du däremot en utvecklare tänker de ofta på mångsidigheten i formatet och du kommer få svar som är förkortningar, i stil med JSONP, eller att de vill ha allt du har i ursprungligt format.
Poängen är att du måste veta vilka dina användare är, och huruvida du verkligen redan vet vad dessa behöver. Annars är det läge att få tag på några representativa användare.
Som vägledning kan du tänka på vilket format som är användbart för att snabbt och enkelt utforska vad datakällan innehåller för information. Det kan ofta behöva kompletteras med format som används för återanvändning i andras applikationer. Det är vanligt att man erbjuder flera olika format så det blir upp till användaren att välja själv. Exempelvis är det smidigast för de flesta att få en Excel-fil när man vid ett enstaka tillfälle vill titta igenom innehållet men man vill hellre ha en CSV-fil, alltså en kommaseparerad textfil, eller liknande om innehållet ska bearbetas maskinellt i en applikation.
Tänk också på i vilken situation dina återanvändare är i – behöver de ladda ner innehållet som en fil eller är det direktanvändning i en mobilapp det handlar om? Det kan ju vara både och, men genom ditt val kommer du styra vilka användare du får. Att erbjuda det mycket populära formatet JSONP är en bra början för att webbutvecklare ska känna igen sig och kunna använda ditt API som deras egen datakälla utan att behöva göra sig omaket att göra en lokal kopia först.
Formatet kan till viss del styras av vilken typ av data man lämnar ut. Är det ekonomisk information kanske ett kalkylark, kompletterat med en CSV-fil, är det mest logiska. Är det nyheter eller kronologisk information är nog grundformatet RSS eller ATOM. Handlar det om geografisk information eller kartdata är kanske GeoRSS, Shape-filer eller KML-filer det du är ute efter.
Många gånger står det i adressen för API-förfrågan vilket format som svaret kommer i. Anledning är densamma som att versionsnumret anges då det blir enklare att förstå källkoden om det tydligt indikeras vad svaret innehåller. Det kan se ut ungefär som adressen för API-förfrågan för att få reda på vem som vann Nobels fredspris 2012:
http://api.nobelprize.org/v1/prize.json?year=2012&category=peace
Felhantering och dimensionering av tjänsten
En del av förutsägbarheten som ett bra publikt API behöver leva upp till är att man på förhand vet hur ett fel kommer te sig rent tekniskt. I vissa API:er jag sett har man till och med kunnat instruera API:et att ge ett fel som svar så man kan provköra sin egen applikation på denna eventualitet. Ett API är infrastruktur andra använder och bör inte komma lindrigare undan med driftsäkerheten än andra viktiga webbtjänster man har.
Det kan få enorma konsekvenser för ett företags anseende om API:et inte funkar. Ett exempel är när Facebook under början på 2013 hade en bugg som gick ut över alla sajter som hade Facebooks Gilla-knapp på sig. Stora delar av webben var inte åtkomlig över huvud taget. Välkända webbplatser som CNN, Huffington Post, ESPN, The Washington Post och många fler gick ner för räkning helt i onödan.
För att den som använder ett API ska ha en chans att själv bygga god felhantering behöver den som ger ut API:et felhantera. Det gäller allt från självklarheter som att använda korrekta felkoder i HTTP, du har säkert sett error 404-sidor när du surfat på webben, till att specifika felmeddelanden är hjälpsamma och utvecklarvänliga.
Det största felet som kan inträffa är nog att ett helt API kan gå ner för räkning på grund av en överbelastning. Det kan bero på många saker varav de flesta är något alla systemutvecklare redan har erfarenhet av. De lurigaste är de som kan anses vara lite överraskande och det galnaste exemplet jag hört talas om handlar om när Stockholms länstrafik (SL) återlanserade sin webbplats i en ny tappning och trodde sig vara utsatta för en överbelastningsattack. I själva verket visade det sig att den tidigare webbplatsen hade ett internt, trodde de, API för att komma åt trafikinformation. Detta API var inte dokumenterat eller utannonserat som en tjänst för andra att dra nytta av men det hindrade inte flertalet populära tjänster och mobilappar från att använda en direkt integration, och beroende till, det API som nu försvunnit.
Anledningen till att den nya webbplatsen gick på knäna var troligen för att det plötsligt blev enorma mängder av felaktiga anrop till webbplatsen vilket kan ta mer prestanda i anspråk än när allt går som det ska. Mer om prestandaplanering kommer senare i denna bok. Lösningen var att rulla tillbaka den gamla webbplatsen, samarbeta med alla de som behövde ett publikt API och sedan återigen lägga ut den nya webbplatsen.
En fiffig lösning många nog inte har är att designa så man kan prioritera trafiken i jobbiga situationer. Om nöden kräver kanske API:et bara ska serva API-utgivaren och betalande kunders webbplatser?
Andra problem som kan uppstå är att man inte har optimerat sitt API för resurssnål användning av andra resurser, som exempelvis databaser, eller så kan det ju vara så att kapaciteten helt enkelt tar slut på grund av en överrumplande popularitet bortom ens vildaste fantasi.
I dagsläget är det så pass billigt att hyra in sig hos en större leverantör att man direkt borde överge det lilla webbhotellet åtminstone för API:et och ha god marginal på de resurser som API:et är beroende av för att fungera. Detsamma kan säkert gälla för de tjänster den interna IT-avdelningen driftar alldeles oavsett om det är en större organisation – om de nu inte kan lova att de erbjuder en motsvarande tjänst.
Best practice är att ha en subdomän i stil med api.minwebbplats.se alternativt data.minwebbplats.se vilket smidigt nog gör att man kan placera API:et hos en leverantör där man kan anpassa prestandan mot efterfrågan utan att det påverkar ens webbplats.
Erbjud kodexempel och visa upp lyckade exempel
Alla som vill använda ditt API är inte nödvändigtvis erfarna systemutvecklare som har gott om tid. Därför kan det som går att återanvända av andra göra god nytta i API-dokumentationen. Till exempel att man i dokumentationen erbjuder tips på hur man enklast kommer igång, kodexempel eller rent utav kompletta exempelapplikationer att ladda hem för andra att jobba vidare med. Kom ihåg att målet med att ha ett publikt API är att andra ska använda det, annars är det smartare att hålla det helt internt.
Var öppen för att länka till resurser som kan vara användara, tipsa om verktyg för att bearbeta informationen och se till att uppmuntra de som använder API:et. Även om de inte betalar för sig är deras användning åtminstone något som motiverar till varför API:et är publikt.
Ett smidigt arbetssätt vissa tagit till är att ha en utsedd kontaktperson som stöttar användarna av API:et genom att ha en utvecklarblogg för nyheter och en wiki för dokumentation. Där kan man få ut information, svara på kommentarer och förbättra den publika wiki-dokumentationen. Det är här man bygger relation till sina återanvändare, en uppgift som kräver teknisk kompetens, social taktfullhet men också en gnutta marknadsmässigt tänkande.
Marknadsför via datamarknader och API-kataloger
För att nå ut med ditt API kan du ta hjälp av diverse API-kataloger för att bli listad. Apikatalogen.se är den med längst historik i Sverige men internationellt är programmableweb.com överlägset störst med tiotusentals listade API:er.
Vissa kataloger, som oppnadata.se, kräver en öppen licensform för inkludering medan andra är mer av en informationshandel där man kan tjäna pengar genom att sälja sina data via tjänsten.

På dessa tjänster kan du se vilken konkurrens det finns inom det område ditt API erbjuder något, vilket kan vara grymt bra inspiration för vad du ska erbjuda i nästa version eller om det är läge för ett samarbete med en annan aktör.
Vilken kvalitet på data behövs?
Ordlista – URI (Uniform Resource Identifier):
En adress till en resurs och ser ut som en helt vanlig webbadress. I sammanhanget kring länkad data används URI som begrepp när man avser att ge en adress, via webben alltså, till något. Du kan se på en URI som ett namn på något - ett namn som råkar vara en adress till en beskrivning av ett ting.
Ordlista – Länkad data:
Data som är kompatibel med andra data och innehåller oftast länkar, URI:er alltså, till dessa platser. Läsbar och förståelig för maskiner genom en informationsmodell som talar om vad det handlar om.
Länkad data är förfinad data som är så väl standardiserad att den kan kombineras med andra datakällor utan att utgivarna ens känner till varandra. Problemet länkad data försöker lösa är att bringa ordning, struktur och sammanhang i den allt större mängden information vi försöker mäkta med – populärt kallat big data. Länkad data är ett sätt att veta om information man snubblar över är relaterad till något annat, om det går att göra vidare efterforskningar.
Precis som webben är ett nätverk av dokument möjliggör länkad data ett nätverk av data i små kunskapspaket och är den naturliga fortsättningen på dagens webb.
Webbens skapare, Tim Berners-Lee, har satt upp fyra principer för hur man länkar data. Nämligen att:
- Använda URI:er för att identifiera sakerDet kan vara ett dokument
på webben, en datamängd eller en fysisk plats med ett syfte i stil med en spårvagnshållplats etc. Detta ger en unik namngivning och ett gemensamt sätt att referera till saker oavsett om det finns på webben eller den fysiska världen. - Använda webbprotokollet HTTP så URI:erna kan kollas upp, läsas av folk och maskinelltMed andra ord ska det finnas en sida på webben där man kan läsa information om en URI oavsett om man är människa eller maskin, går in via en skrivbordsdator eller annan typ av enhet som anropar.
- Ge nyttig information när URI:n kollas upp och då använda standardiserade format som RDF/XML. I denna information ges vad något har för status, vem som ansvarar för något, nyckelord etc.
Om anropet görs av en maskin kommer maskiners fikonspråk, troligen RDF, användas men om det är en vanlig människa via en webbläsare kan man istället få lite mer lättläst information tänkt för människor. - Inkludera länkar till andra relaterade URI:er för att möjliggöra hänvisningar och för att upptäcka relaterade URI:er på webben. Det kan vara släktskap till annan information där hänvisande URI ges, bland annat att en viss URI ersätter en tidigare likt en adressändring när man byter bostad. Alla kända och användbara referenser ges här och listan kan vara lång med såväl organisationsinterna som externa URI:er.

Brittiska BBC byggde sin tjänst iPlayer Radio baserat på länkad data vilket gett ett härligt Wikipedia-flöde med korslänkning på tjänsten, information som relaterar till det som spelas automatiskt plockas in från externa länkade datakällor. Denna integration med externa källor är kanske lite mindre hårt styrt än det brukar vara vid traditionell användning av andras API:er. Länkad data använder många olika tekniker som möjliggör en löst kopplad sammanslagning av flera informationskällors innehåll. Visionen är att hela webben ska bli som en enda stor databas lättillgänglig för oss alla.
För att det ska vara lönt att själv bidra med egen länkad data bör ens information kunna relatera till någon annan informationssilo eller att man är den naturliga utfärdaren av URI:er för något unikt.
Man kan ha nytta av principerna från länkad data utan att ha för avsikt att sprida sin information utanför organisationen, exempelvis för att införa en systemövergripande namngivning på viktiga ting. Likt personnummer är en begriplig referenspunkt för samkörning mellan informationssystem kan man för vad som helst använda URI:er för att uppnå samma standardiseringsfördelar – istället för att saker heter olika i varenda databas.
Mikrodata – semantiskt beskrivet innehåll
Ordlista – Semantiska webben:
Avser de webbplatser där innebörd och informationens typ kan förstås av maskiner. Detta gör att webben blir mer av en stor databas. Ett nät av data och inte bara ett nät av webbdokument.
Nämn ordet semantiskt och kollegorna får något glasartat i blicken, tro mig jag har testat många gånger. Det är inte så krångligt eller tråkigt som ordet verkar ge sken av. Den semantiska webben, eller webb 3.0 som vissa kallar den, är den generation av webben vi idag ser. Den lite mer intelligenta webben. Den som väger in din plats i relevansmodellen för vilken bilverkstad du troligen är intresserad av – att den som är nära och har massvis med positiva recensioner rankar högre än den fullkomligt okända verkstaden utan publika kontaktuppgifter som finns jäkligt långt bort från dig.
För att detta ska fungera krävs det mer tydligt beskriven information av den enkla anledningen att ingen har tillgång till all information i ett strukturerat format. Den är utspridd på många tjänster som behöver kunna samverka. Bland annat sökmotorer är utlämnade till hur väl beskriven information är på webbplatser och andra datakällor de inte själva har kontroll över. Här kommer mikrodata in som en räddare i nöden för hur ens webbplats kan vara en del av allt detta med att bringa lite mer ordning.
Har du använt en sökmotor de senaste åren är det högst troligt att du redan haft nytta av semantiska funktioner. Poängen är att sökmotorer och andra tekniska system försöker förstå vad för strukturerad information som ingår i texterna. För människor är detta enklare än för maskiner då vi kan förstå vad en text handlar om bara genom att läsa. Möjligheterna för sökmotorer att förbättra sin förståelse av ostrukturerad brödtext börjar snart nå sin gräns för att inte tala om hur de ska förstå innehållet i ett videoklipp eller annan media.
Den mest grundläggande nivån alla förhoppningsvis insett vid det här laget är att skilja på rubriker och övrigt innehåll i text. Det är nu för tiden inte lika vanligt att man ser att underrubriker är fetstilad brödtext på en egen rad eller att rubriker är bilder istället för text. Precis som rubriker vägleder oss seende när vi skummar igenom en text finns de också där för att ge en dokumentstruktur som är maskinläsbar. Att en maskin kan förstå att en viss text är en rubrik är det som gör att även blinda kan skumma igenom en text tack vare att lyssna på dess rubriker innan de väljer att eventuellt få någon del uppläst.
Andra sammanhang där rubriker används är för att mäta relevans på en text. Om ett sökt ord finns i en rubrik på sidan är det troligen något mer relevant än ett annat där ordet bara finns i brödtexten. Detta används bland annat i merparten av dagens sökmotorer.
Att identifiera vilka typer av information din webbplats innehåller och märka upp dem korrekt kan inte anses vara valfritt arbete längre. Lista saker som kontaktuppgifter, kalenderhändelser, geografiska punkter etcetera och leta upp en lämplig standard som beskriver informationen. Några av standarderna kommer vi gå igenom strax.
Så, vad är då problemet?
Räkna själv på fingrarna hur många varianter av datum du stött på. Troligtvis kan du hitta en variant i din kalender, en annan i eposten och en uppsjö på varorna i matbutiken. Åtminstone jag surar alltid när datum anges i stil med 06/11/10 då jag inte vet vilken standard det följer.
Att siffran 29 står under månaden augusti i din kalender är enkelt att förstå för oss människor. Hittar du en webbplats, klickar på kalender och får samma information kommer vi troligen att förstå detta även i det sammanhanget. Dock är det inte givet att en maskin som läser texten förstår något sammanhang över huvud taget. Lägg därtill att det finns massor med olika nationella standarder och branschstandarder som anger hur datum och tid ska skrivas. Ett veckonummer i datumsammanhang är ytterligare ett problem då det råkar vara några europeiska länder och ett fåtal i Asien som ens har ett begrepp om att veckor kan ha ett nummer.
Detta problem begränsar sig förstås inte till tidsbunden information. Bland många exempel är avstånd, geografisk plats och enheter som vikt värda att nämna. Egentligen finns problemet i all information.
Möjligheterna med semantisk information
En av flera drömmar som återstår att förverkligas på internet är att webben ska kunna vara som en gigantisk databas med en struktur så man kan få otvetydiga svar på sina frågor. Just nu är webben en halvstrukturerad databas där det är svårt att veta vad som är vad, åtminstone för maskiner.
De som intresserar sig för sökmotoroptimering har säkert stött på Googles begrepp rich snippets vid det här laget eller läst tips om att man ska jobba med något som kallas för RDFa. Rich snippets antyder mycket lämpligt att det är berikade snuttar av information som är självbeskrivande för en maskin. Jag har inkluderat några exempel på hur det kan se ut när sökmotorn Google visar upp mikrodata den funnit på en webbsida. Förutom möjligheten att lyfta ut fler delar av sin webbplats direkt till sökmotorn visar man också besökaren att det finns mer relaterad eller ordnad information att ta del av på webbplatsen.






Nu är det inte bara för sökmotorernas skull man märker upp sitt innehåll. Andra användningsområden är vad du som besökare på en webbplats kan göra med informationen. Bland annat att kunna klicka på ett telefonnummer på en webbplats och direkt ringa, importera kontaktuppgifter till adressboken och lägga in en händelse i din kalender direkt från en webbplats.
Att man som användare kan dra nytta av semantiskt uppmärkt information har inte direkt tagit de flesta användarna med storm. Nu finns det en chans att det förändras när webben allt mer används via andra typer av enheter där avsaknaden av tangentbord och mus kan lindras med dessa möjligheter och informationen kan användas på ett mer intuitivt sätt anpassat för respektive typ av enhet.
Att betrakta webben som en utspridd databas, eller ett enormt dokumenthanteringssystem, är kanske inte så märkligt. Det semantiken tillför är att sätta dokumenttyper på respektive sida eller delmängd inom en sida. Innehåller en sida kalenderinformation och geografisk plats hjälper det till när andra system ska ge dig som användare ett urval i en större informationsmängd baserat på vad du letar efter – innehållet kan berätta vad den är för något utan att du tvingas lusläsa allt först.
Standarder som Schema.org och Microformats
Att använda Microformats eller Schema.org är de två vanligaste sätten att utöka semantiken på webbsidor idag. De båda består av ett antal specifikationer för hur HTML-koden ska se ut för att sticka ut ur mängden av brödtext och annan HTML. Microformats släpptes tidigt som en standard under utveckling med tanken att ge enkla knep som utökade HTML-standarden för mer semantisk innebörd för bland annat kontaktuppgifter.
Det går ut på att man justerar sin HTML-kod för att följa vissa mönster (se exempel senare) där det i koden går att ange information i ett visst format och ha något annat mer läsvänligt som visas på själva sidan. Tekniken i sig kallas för RDFa (Resource Description Framework in Attributes) vilket som du kan se i kodexemplet är ett sätt att med attribut berika koden med vad innehållet är för typ av information.
Exempel på kod i Microformats för att beskriva ett företags kontaktuppgifter
<ul class="vcard">
<li class="fn">Nils Hult</li><li class="org">Exempelföretag AB</li>
<li class="tel">08-12 34 56</li>
<li><a class="url" href="http://exempel.se/">http://exempel.se/</a></li>
</ul>
Geografisk position enligt Schema.org för plats i Umeå
<div itemscope itemtype="http://schema.org/Place">
<span itemprop="name">Bräntbergets Skidlift, Umeå</span>
<div itemprop="geo" itemscope itemtype="http://schema.org/GeoCoordinates">
<meta itemprop="latitude" content="63.841066" />
<meta itemprop="longitude" content="20.311139" />
</div>
</div>
Schema.org är en standard som lanserades av Google, Yahoo och Bing under sommaren 2011. Det är en gemensam ansträngning för att råda bot på att Microformats utveckling bromsat in kraftigt sedan 2005. Schema.org är det du väljer om du ännu inte börjat med mikrodata i din information.
Det finns en lång lista över mikrodata som kan användas för att berika information. Här följer en kortare lista för att exemplifiera bredden:
- Kontaktuppgifter och författarskap.
- Geografisk position.
- Händelse/evenemang.
- Person och organisationer.
- Hälsouppgifter.
- Produkt, erbjudande.
- Bok, film, recept, målning.
Många av dessa kan dessutom kombineras för att ge en geografisk position i ett företags kontaktuppgifter. Full lista hittar du på följande adress schema.org/docs/full.html
Vad denna strukturerade data sedan används till varierar från tjänst till tjänst. Hur det ser ut på Google är ju något vi alla ser ganska fort och är en del i att sökmotoroptimera dels för att locka in besökare från sökmotorn men anses också öka sidans värde i sökmotorns ögon. Bättre struktur är ett kvalitetsmått många av oss kan bli ännu bättre på. Det finns inget som hindrar andra aktörer att dra nytta av samma information till egna tjänster – alla dessa mikrodata ligger ju på webbplatser lika publika för dig som för Google, som för en organisationsintern sökmotor.
Digital resurshantering (och Adaptive Content)
Ordlista – Digital resurshantering:
Går ut på att samla, beskriva, bevara och använda digitala resurser i ett användbart arkiv. Går ibland under namnet bildbank men innehåller oftast mer än enbart bilder. Ofta kallat DAM (Digital Asset Management) eller MAM (Media Asset Management).
Ordlista: Adaptive Content Management:
I mångt och mycket samma sak som DAM men med fokus på flerkanalsproblematik, exempelvis att man vill servera olika versioner av material beroende på typ av enhet det ska konsumeras på, bland annat mobiler, skrivbordsdatorer, kroppsnära enheter, tv-apparater i skyltfönster etcetera.
Nyttan med digital resurshantering (hädanefter kallad DAM och inbegripande Adaptive Content om inte annat anges) är primärt två saker, nämligen, först och främst, att ha en central plats för lagring och hantering av alla mediafiler så de kan återanvändas om och om igen. Utöver behovet av ordning och reda, att ha en plats att leta i eller integrera andra system mot, är DAM-systemet ofta det verktyget som ansvarar för distribution av detta material till andra informationssystem. Det är enklare, i ett enterprise-scenario, att se till att man har ett system som är kompetent inom att optimera bilder för webben än att alla webbsystem ska behöva kunna detta, eller att strömma video anpassat efter tillgänglig bandbredd hos mottagaren. Inom stora organisationer är det inte bara vanligt med många system som är tillgängliga via webben utan man har ofta flertalet webbpubliceringsliknande plattformar som kan ha stora svårigheter med att leva upp till webbens föränderliga krav.
DAM beskrivet på Wikipedia:
“Digital asset management (DAM) consists of management tasks and decisions surrounding the ingestion, annotation, cataloguing, storage, retrieval and distribution of digital assets. Digital photographs, animations, videos and music exemplify the target areas of media asset management (a subcategory of DAM).”
Det här med DAM-system kanske inte är något för dig som driver en personlig WordPress-sajt, men att betrakta alla sina mediafiler, som bilder och ljud med flera, som digitala resurser kan löna sig ändå. Dagen kan komma när man frågar sig varför man inte hade en mer förutseende struktur på sina filer direkt när man började.
Likheterna med en ordnad dokumenthantering för en större organisation är slående. Det handlar om att bevara originalfilerna, standardisera metadata som sätts på varje fil, kontrollera vem som har behörighet till vilka filer och lämna ut fungerande läskopior via exempelvis webbplatser. Exemplifierat med ett fotografi är originalet gärna i ett digitalt råformat direkt från kameran, metadata beskriver bildegenskaper som tidpunkt för kortet och dess slutartid, behörigheten vem som har rätt att använda bilden och läskopian via webben är en JPG-bild optimerad för webben.
Exempel på filer som kan ingå i ett DAM-system:
- Fotografier.
- Illustrationer, informationsgrafik och bilder.
- Broschyrer, grafiska produktioner och andra trycksaker.
- Videoklipp och filmer.
- Ljudklipp, poddsändningar och ljudeffekter.
- 3D-printerfiler, CAD-filer och andra digitala ritningar.
Det man oftast inte tar med är de mest uppenbara dokumenten likt ordbehandling och kalkylark. Exakt var man drar denna gräns kan vara rätt svår och jag har sett exempel på DAM-system som även lagrat Excel-filer. Kanske för att DAM-systemet gjorde ett bättre jobb än dokumenthanteringssystemet.
Ofta ingår de mest grundläggande redigeringsmöjligheterna i ett DAM-system, exempelvis att göra en beskärning av en bild. Denna redigerade version av materialet lagras som en kopia av originalet så det går att följa upp användningen av en bild.
Exempel på faktorer som gör behovet av ett DAM-system stort istället för att använda uppladdningskatalogen på sin webbplats kan vara:
- Behörighetsstyrning som att inloggade besökare på en bildtjänst får se en viss bild och ej inloggade ser en väldigt lågupplöst version med text som uppmuntrar till registrering på webbplatsen.
- Särskild åtkomst för att ge inhyrda fotografer eller tryckeri åtkomst till gemensamma projektfiler så man slipper springa runt med USB-minnen.
- Hantering av flera kanaler där ett DAM underlättar att ha en samlad plats för styrning av kommunikation ut mot det växande antalet enheter och kanaler som används.
- Personalisering som att besökare får material som är populärt i deras geografiska närhet eller till video automatiskt erbjuda undertexter i ett språk de förstår.
- Enhetsanpassning genom att skicka material i hög DPI om det stöds, eller att skicka i de format som är bäst lämpat för enheten.
- Uppkopplingsanpassning för att skicka exempelvis strömmande video anpassat efter att inte lagga i mottagarens enhet men i med bästa tänkbara upplösning.
- Miljöfaktorer där besökaren har ont om batteri i sin mobil begränsas mängden nätverkstrafik, eller att anpassa materialets kontrast efter ljusförhållanden runt besökaren.
- Målgruppsanpassning så den information som skickas är begriplig för mottagarens kunskapsnivå, detta löser man genom att relatera olika versioner av innehåll som klassificerats efter målgrupp.
- Legala behov där man använder bilder från en extern bildbank och behöver hålla ordning på vilka licenser dessa bilder har, eventuellt tidsbegränsad publicering.
- Hittbarhet då det underlättar att hitta materialet om det finns på en enda plats, troligen med mer konsekvent metadata-hantering än om det sköts i olika system.
- Effektanpassning för att genomföra A/B-testning och att systemet efter testningen skickar det material som fungerat bäst hos mottagarna.
- Analys av användning är något fler borde bry sig om. Vet du hur många nedladdningar filerna i din uppladdningskatalog har? Det kanske är ditt populäraste innehåll. Direktlänkas det från andra webbplatser till ditt material? Om allt material finns på en plats blir det enklare att få koll.
Hoppsan Kerstin, kanske du tänker. Allt det där är ju inget som bekymrar dig med din lilla webbplats. Kruxet är bara att behovet av denna typ av ordnad hantering smyger på en över tid och det är väl aldrig en attraktiv tanke att stanna upp med allt man håller på med?
Säg att du tagit en grymt bra bild på chefen, den bilden kan få spridning på bland annat dessa digitala vägar:
- Egna webbplatsen under kontaktinfo.
- På intranätet.
- I personalsystemet och på personens ID-kort inom organisationen.
- Den mobila webbplatsen.
- I mobilappen och surfplatteappen.
- I trycksaker som årsredovisningen.
- E-postutskick som nyhetsbrev.
- Interna och externa bloggar.
- Mikrobloggar, likt Twitter som profilbild.
- Sociala medier på officiella konton.
Att med bara några av ovan tänkbara scenarier slarva bort originalet gör livet bökigt vid behov av bilden i ny beskärning. Allt officiellt använt material gör sig bäst på en gemensam plats sökbar av alla som behöver kunna kommunicera. Att ha ett DAM-system i en välfungerande symbios med vem som helst ute i organisationen, inte under total kontroll av en gammaldags trycksaksorienterad kommunikationsavdelning alltså, är en våt dröm.
Utmaningen med ett DAM-system är att det inte blir bättre än sitt innehåll eller struktur. Vem ska få lov att bidra med innehåll? Vem som helst, eller enbart en kvalificerad mediaredaktör?
Själv skulle jag nog föredra att man kör en mix. Kanske två olika zoner. Den demilitariserade zonen där organisationens accepterade resurser återfinns – oftast temabilder. Sedan finns platsen där olika nivåer av kaos råder. Likt Dantes kretsar av helvetet finns flera nivåer av struktur i det användargenererade materialet. Detta sköts genom tröskelvärden satta av organisationen och de som bidrar med material kan själva välja nivå av hittbarhet för sitt material. Har denne för avsikt att låta andra återanvända något hjälper DAM-systemet till med metadata och att ställa in behörigheter annat än privat för skaparen själv. Detta görs med fördel genom att ett uppmuntrande, kanske innehållande spelbaserade mekanismer, gränssnitt vägleder upphovsmannen genom processen att ge tillräckligt mycket information att det finns en chans att någon annan finner materialet vid ett senare tillfälle. En variant är att kräva ett visst minimum av nyckelord och kategorier för att det ska gå att spara sin bild för andra att se och söka efter.

Nyckelord som anges kan behöva få en grafisk presentation snarare än att man ska förstå att skriva ett komma mellan varje nyckelord. Att få stöd via redan förekommande nyckelordsförslag är en god idé för att skapa någon form av enhetlighet i sin nyckelordsmärkning.

Informationskällan som ger nyckelordsförslag kan vara en centraliserad metadatatjänst som håller de vokabulär man använder och som vårdar ens egna folksonomi. En sådan metadatatjänst skulle förstås användas även av alla andra informationssystem. Det är viktigt att metadatatjänsten inte bara föreslår ord utan också har unika identifikationer på varje ord då de kan förekomma på fler platser i vokabulär som har en trädstruktur, eller om man nu har flera liknande ordlistor man behöver hålla isär.
Den media som märks upp med ett nyckelord behöver ha koll på både ordet som klartext men också det unika ID:et för nyckelordet som referens till metadatatjänsten. Då blir det lättare att i framtiden flytta ett ord från folksonomin till ett mer ordnat eget vokabulär då man slipper ändra metadata på allt material som sedan tidigare märkts upp med ordet från folksonomin. Det skulle också hjälpa till om man bestämmer sig för att gå igenom sin folksonomi i jakt på synonymer man vill associera med varandra.

Tänk också på om det finns andra metadata som behöver anges för att informationen ska bli riktigt användbar. I ärlighetens namn är det nog inte troligt att den magiska dagen inträffar då man får tid att fixa det i efterskott. Video- och ljudklipp kan behöva ha tidskoder för när olika avsnitt inträffar inuti klippen – det är deras motsvarighet till de för text så självklara rubrikerna som hjälper oss skumma igenom innehållet lite mer översiktligt. På Youtube kan man exempelvis högerklicka på videoklippet och får en specifik länk till den exakta positionen i klippet, men man kan också i kommentarerna till videoklipp skriva i formatet minuter:sekunder så kommer en länk skapas som hänvisar till den angivna positionen i klippet. Detta är motsvarigheten till kapitel i en ljudbok eller DVD-film. Anges denna information i det centrala DAM-systemet underlättar det förstås när man i sina poddsändningar vill få med kapitel för lyssnaren att använda precis som det är lite av en automatisk innehållsförteckning. Du som flitigt använder Apples app Podcaster kanske märkt att omslagsbilden i en poddsändning kan förändras per kapitel vilket lämpar sig för bland annat DJ:s som vill ha originalartistens omslag på bilden till kapitlet.

Det finns också metadata-standarder för de specifika typerna av filer. Ett fotografi innehåller EXIF-data med information om slutartid och andra kamerainställningar vilket kan komma till nytta. ID3 är ett taggningssystem för ljud och musik som kan vara värt att följa då det bäddas in i mediafilen och således följer med filen när den sprids för vinden.
Adaptive Content
Adaptive Content, som i anpassningsbart innehåll, dök upp som begrepp runt 2012 och är en delmängd av det många nog skulle förvänta sig av en fullfjädrad DAM-strategi. Det adresserar utmaningarna med att ha god koll på innehåll oavsett vilken kanal den kommuniceras ut i, men främst är det förstås mobilt många bekymrar sig över. Målet är, likt tankarna kring responsiv webbdesign, att innehållet ska visa upp sig efter bästa förmåga under de förutsättningar som ges.
”Think of your core content as a fluid thing that gets poured into a huge number of containers. Get your content ready to go anywhere because it’s going to go everywhere.”
Brad Frost, tba.nu/evr

Gör man ett videoklipp för spridning är det ju bra om det skickas i ett optimerat format för respektive kanals möjligheter att leverera resultat. Ibland snubblar man över exempel på när det inte blir som det var tänkt, eller att man struntat i vilket. Bland annat noterade jag att Elgiganten körde en kampanj i sitt skyltfönster där man körde ut en reklamfilm för liggande bildformat fast man monterat skärmarna stående. Först förstod jag inte vad det var som såg skumt ut, men så fort jag såg den äggiga formen på Porschens hjul trillade polletten ner. Är proportionerna i filmen fel på grund av att man aktivt valde bort att lägga en svart list ovan och under bilden? Gick det inte?
I sitt egna skyltfönster har man troligen inte problem med bandbredden och kan visa bästa tänkbara upplösning och utan onödig komprimering. Samma videoklipp på webben behöver massvis med komprimering – särskilt om den ska strömmas då man riskerar att få lagg i uppspelningen om nedladdningen inte går fort nog.
Det kanske är enklare att tänka sig detta i form av stillbilder då man i annonssammanhang, som hos Google Adwords med flera, har ett antal standardstorlekar att förhålla sig till. Så borde man också se på bilder man själv lagrar i sitt DAM-system för egen användning med skillnaden att se till innehållets behov, och möjligheter, hos den mottagande enheten. Den svåra balansgången är att inte skapa mängder av optimerade innehåll för varje mottagare utan att istället försöka täcka in så många scenarier som möjligt.
”Fragmenting our content across different ’device-optimized’ experiences is a losing proposition, or at least an unsustainable one.”
Ethan Marcotte, författare av boken Responsive Web Design
Nu är det ju inte bara proportioner eller storleken på bilder som är utmaningar. Listan kan göras ganska lång beroende på vad man anser ska ingå i DAM-systemets stödfunktioner för flerkanalskommunikation. Själv skulle jag lägga in att detta system, oavsett om något annat av ens innehållssystem också kan det, ska klara av att skicka situationsanpassat material där den konsumerande enhetens möjligheter beskriver behoven i en form av önskelista. Sedan får man lista alla egenskaper man har behov av att ta hand om, exempelvis kan nedan ingå:
- Stillbilder för skärmar med normal eller hög upplösning (vad Apple-användare kallar retina).
- Välja om videomaterial ska kunna strömmas och/eller laddas ner.
- Upplösning på material ska kunna variera beroende på vad det återanvändande systemet har för önskemål eller vad mottagande enhet klarar av.
- Komprimeringsgrad ska automatiskt anpassas och kan väljas manuellt. Ett val är att avstå komprimering för filer som tagits fram med professionella verktyg.
- Format kan bero på mottagaren. Text kan komma som Word, HTML, PDF, Markdown med flera.
Vad skickar du till en iPhone 6s med sin retina-skärm som hålls i landskapsläge när den är uppkopplad på ett mediumsnabbt mobilnät och användaren befinner sig ute i solen?
Det blir lite av matchmaking. Vill du helst återvinna en gammal annons i Flash-format? Kan enheten som efterfrågar materialet visa upp Adobes Flash, eller ska en lista av andra alternativ du gett gås igenom innan det som skickas kanske prutats ner till en stillbild, eller inget alls? Ibland kanske det är meningslöst att ens försöka skicka något och man bör be mottagaren om en mejladress att skicka materialet till.
Poängen med adaptive content är att man mäter hur väl ens val faller ut hos besökarna. Detta görs lämpligen med A/B-tester vilket är en form av tävling mellan två alternativ (alternativ A och alternativ B) som slumpas ut till besökarna under en begränsad tid. Den som fungerar bäst är den som fortsätter användas efter den begränsade testtiden. På detta sätt når man kunskaper om vad som fungerar i respektive situation hos användarna. Vad som funkar kanske skiljer sig mellan skrivbordsdatorer och mobiler, eller annan segmentering?
Bild- och mediabanker i ditt publiceringssystem
För den mindre organisationen, eller de med lite mindre krav, kan det säkert duga med en av de bildbanker man kan få integrerat och klart till sitt publiceringssystem. Dessa system har lite olika fokus. De jag använt är Imagevault som har lite DAM-funktionalitet och ett helt ok API men främst är en vanlig kombination med publiceringssystemet EPiServer. Det andra systemet är Fotoweb som mer är en komplett svit för de som behöver avancerade sökmöjligheter och integration med de program professionellt folk i grafisk industri använder, exempelvis Adobe Indesign.

Innan man väljer ett så pass nyckelfärdigt system bör man ha klart för sig vad som står på önskelistan. Kanske kan följande vara viktigt för dig:
- Korrekt upplösning ska skickas oavsett storlek på bild i systemet.
- Bilder ska skickas optimerat för webben. Ska det gå att ha undantag från systemets optimering utifall det i vissa fall ger dåligt resultat. Manuell kontroll?
- Behöver det kunna hantera video? Strömmande och/eller nedladdning?
- Behörighetsstyrning eller är alla filer för allas användning?
- Ska högupplöst material kunna skickas till retina-skärmar?
- Är det enkelt att lägga in lånade bilder och hålla koll på användningsvillkoren man accepterat?
För den som vill ha manuell stenkoll på optimeringen av en bild kan jag, förutom Adobe Photoshop, rekommendera verktyget ImageOptim för Mac som jag är nöjd med. Bara dra och släppa bilder eller mappar i fönstret och så fixar den hela kalaset. Kolla in det på tba.nu/optim
Yahoos Smush.it är en tjänst att ta till om man vill ha automatiserad optimering av bilderna. Den är dessutom i det närmsta förlustfri för det mänskliga ögat – tba.nu/yoptim
Personligen tror jag manuell bildhantering duger för de flesta om man har god struktur i sin bildbank i publiceringssystemet. Om man vill ta sin bildhantering för webben lite mer seriöst i form av ett DAM-system är det ett hyggligt stort projekt att kicka igång.
Personalisering
Med hjälp av meningsfull metadata får man fler friheter i vad man väljer att visa upp för besökaren på en webbplats. Personalisering går ut på att matcha innehåll mot en relevant mottagare och vara proaktiv i sin kommunikation. Vad som visas är styrt av metadata – metadata om innehållet och metadata om den tänkta typen av besökare.
Personalisering handlar inte om att göra innehållet personligt, däremot individ- och situationsanpassat när det presenteras vilket fungerar i viss utsträckning även när man inte vet vem individen är.

Du har garanterat varit på en tjänst som lyckats profilera dig och ge dig personaliserat innehåll. En personalisering jag ofta stöter på är i Googles högra fält för Knowledge Graph där saker jag sökt efter dyker upp med en geografisk närhet som avgörande personaliserande faktor. Medicinhistoriska museet i Göteborg valdes i högerkolumnen framför motsvarande museum i Uppsala. Antagligen för att jag befann mig i, eller är associerad till, Göteborg.
Det finns två typer av data om en besökare, nämligen:
- Explicit data vilket besökaren själv lämnat ifrån sig genom att vara inloggad kund med ifyllda kunduppgifter, ifyllda formulär och annan aktiv delgivning av information.
- Implicit data som handlar om att besökarens beteende kan avslöja information som speciella intressen, vilket kön besökaren har med mera.
Exempel på vad du kan tänkas veta om respektive besökare är:
- Var de befinner sig? Det finns många tekniker för att med mer eller mindre stor säkerhet avgöra var en person troligen befinner sig.
- Vilken utrustning används? Använder besökaren en dator, surfplatta eller mobiltelefon påverkar det beteendet och vad de är ute efter med sitt besök. Exempelvis kommer du troligen inte köpa ett hus via mobilens webbläsare men att bläddra bland bilder eller leta fakta är nog
vanligare. - Om det är deras första besök, eller ett återbesök? Om det finns tidigare besök kan cookies användas eller om besökaren är inloggad kan man spara uppgifter utan användarens aktiva medverkan. Tittade besökaren på något väsentligt vid sitt föregående besök? Övergav denne någon kundvagn med innehåll som kan vara värt att lyfta fram? Till viss del kan man dra nytta av så kallad remarketing, via bland annat Googles annonssystem, för att styra in återbesök till en landningssida optimerat för dessa besökare.
- Var befann sig besökaren innan denne hamnade på din sida? Gjordes det en sökning på något specifikt hos en sökmotor, länk från ditt egna nyhetsbrev, eller kom besökaren från en sida med ett sammanhang som gör att innehållet på din sida borde påverkas – exempelvis en kampanj på sociala medier.
- Finns information om besökarens preferenser? Är det en inloggad kund kan man samla egen data. Driver man exempelvis en videotjänst finns säkerligen slutsatser att dra på vilken kategori av video en besökare tenderar att se på, favoritmarkera etc. Fundera på om det finns sådana data du kan dra nytta av. Vilket språk som valts på webbplatsen avslöjar säkert mer än modersmål, vilka böcker som säljer bra på Adlibris varierar garanterat med vilket språk besökaren kan.
- Avslöjar deras navigationsbeteende något? Om en besökare håller sig inom en kategori av innehåll, eller konstant hoppar mellan olika, kan förklara ett eventuellt intresse eller möjligen en önskan om att bli överraskad. Att besökaren använder sökfunktionen kan, om du har koll på din sökanalys, vara något som förklarar vad de är ute efter.

I praktiken bygger man upp kategorier av tänkta besökare, en behöver nog vara Övriga där man ännu inte har något specifikt innehåll att styra fram – vilket motsvarar icke-personaliserade webbplatsers standardläge. Om tillräckligt mycket information om en besökare pekar på en viss kategori faller denne över tröskeln och får riktad information mot den kategorin av besökare. Dessa kategorier är att se som vägledande för vad som dyker upp på sidan, vissa saker kan ändå tillåtas varieras för besökare inom en kategori. Exempelvis vill nog reseföretagen gärna försöka ange din närmsta flygplats för avresa oavsett vilken personaliseringskategori du hamnat i.
Exempel på personaliserat innehåll
Så som detta hanteras är att om det finns tillräckligt goda skäl att påverka sidans innehåll görs en justering efter en på förhand given mall. Det kan vara exempelvis vilka produkter man puffar för eller påverkar vilket kontors kontaktuppgifter som visas. Detta görs med hjälp av tröskelvärden. Dessa trösklar kan man lägga på olika nivåer beroende på vad det handlar om. Du kan se det som att i exemplet med kontaktuppgifter för ett internationellt företag uppstår en tävling mellan besökarens geografiska närhet och språkval. Tröskelvärdenas funktion är först och främst att ange om en besökare kvalificerats in i en kategori och sekundärt avgöra vilken, om flera, kategorier som vinner.
Ta scenariot med en global sportbutik exempelvis. Om besökaren bor på norra eller södra delen av jordklotet är ganska avgörande för vilken typ av varor som är av aktuellt intresse på grund av att årstiderna är motsatta. Jämför det med en global musikbutik där det också finns regionala skillnader men troligen inte lika dramatiska – här handlar det snarare om att erbjuda det man kan leverera på besökarens marknad.
För att kort återgå till exemplet innan från Adlibris – var tror du man helst ska lyfta fram kurslitteratur för högskola? Kategorin ”Privat” eller den för ”Bibliotek, företag och offentlig förvaltning”? De uppdelningar är garanterat där för att kunna positionera mer relevant innehåll för de olika kategorierna av besökare, dock är det inte alltid så tydligt att man själv som besökare måste välja ett navigationsspår.
En underklädesbutik vill nog gärna veta sina besökares kön för att en vanlig dag plocka fram kalsonger till en man men inför vissa högtider lyfta fram presenttips till en statistiskt sannolik flickvän. Finns det något mönster i besökarens surfbeteende som avslöjar kön? Går det att få reda på besökarens kön via något externt annonssystem?
Volvo kan tänkas göra skillnad på de som tänker skaffa en Volvo och de som redan har en. Behoven är lite olika. En presumtiv kund kan behöva tips om finansiering via Volvo Finans medan den som redan äger en Volvo kanske behöver påminnas om nyttan med originalreservdelar och auktoriserade verkstäder. Inte nog med det, de försöker få veta hur nära köp respektive person är.
”Volvo kartlägger användarna baserat på hur köpbenägna de är. De som bedöms vara långt ifrån köp vill se produkter, bilder och filmer. De som är närmre köp vill kunna boka testkörning, göra detaljval och få prisuppgifter. Därför presenterar vi olika innehåll utifrån användarens besökshistorik.”
Mikael Karlsson, mobilchef på Volvo Car Corporation, tba.nu/refcio

Det är inte alla som är lika uppenbara som Dustin. Vid besök på dustin.se promptas man om man vill ansluta som företag eller privatperson. Väljer man företag kommer priser automatiskt visas exklusive moms och kampanjer på att köpa servrar och nätverksutrustning visas på startsidan. Väljer man istället versionen för privatpersoner kommer en snarlik webbplats upp, med annat färgtema, där priser är inklusive moms. Här puffas för surfplattor, tv-apparater och grafikkort för de som gillar att spela.

Den kanske simplaste varianten är 1177.se som utifall det går att avgöra vilket landsting/region besökaren befinner sig i skickas vidare till en regionaliserad landningssida. Själv hamnar jag på Västra Götalandsregionens undersida vilket även syns i adressfältet, det påverkar vilka nyheter, puffar och annat jag får se. I de fall det inte går att avgöra besökarens position kommer man till en neutral nationell variant. Två kategorier alltså; positionerad med säkerhet inom landsting och alla andra.
I ett publiceringssystem är det viktigt att det finns en koppling till besöksstatistik för redaktörer så inte innehåll skapas som aldrig kan nå en besökare på den personaliserade webbplatsen.
På vilka sätt kan du kategorisera dina besökare/kunder? Utan att irritera dem? Något som garanterat irriterar dina besökare är när de försöker följa en död länk. Dags att prata lite URL-strategi.
URL-strategi för dummies
Ordlista – URL (Uniform Resource Locator):
Är den fullständiga adressen till en webbsida eller resurs på nätet. Exempelvis http://webbplats.se/kontakt/ enligt syntax protokoll://domän.toppdomän/undersida-eller-fil.extension
Kallas ofta för webbadress, eller adress kort och gott.
URL:er är webbens adresser och används för att ha en gemensam referens till något. Detta något kan vara startpunkten på en webbplats, en undersida, en bild eller annan typ av resurs. URL:er är viktiga för att människor och datorer ska kunna adressera webbsidor, uppladdade filer eller data. Precis som en fysisk gatuadress förväntas bestå över tid är det bra om en adress som etablerats lever länge och har ungefär samma innehåll vid nästa återbesök.
Det kan vara enkelt att glömma bort vad som händer när man skapat en ny sida eller lagt upp nytt material. Om det som lagts ut rönt uppmärksamhet riskerar en bruten URL att följande inträffar:
- Länkar från andra webbplatser till din bryts.Det kan vara så att
URL:en används på någon annans intranät, vilket inte går att ta reda på förrän man eventuellt ser ett visst mönster i statistiken till sin Error 404-sida. - Folk som lagt till bokmärken hamnar på en felsida.Numera används inte bokmärken i webbläsare i samma utsträckning som förr men det är inte irrelevant ännu.
- Webbplatsen tappar värde hos sökmotorerna.Det kan vara riskabelt, särskilt för de som är beroende av sökmotorer för sin trafik, att skrota många adresser sökmotorn känner till. Dels för att en äldre URL alltid är mer värd än en ny, men också för att det finns en misstänksamhet inbyggd i sökmotorernas algoritmer – de för trots allt en hård kamp mot sökmotorspam.
Sökmotoroptimerarare jobbar hårt för att få naturliga länkar och ingångar till webbplatser. Sett med deras ögon är det förstås ett otroligt slöseri att inte intressera sig för att ta hand om inarbetade adresser som redan används av andra eller är kända av sökmotorerna.
Kvalitetsindikatorer för en URL är att den ska:
- Vara utformad för att kunna bestå över mycket lång tid.
- Ange vem som är avsändaren.
- Beskriva vad som finns på adressen.
- Vara så kort som möjligt, inte innehålla oväsentligheter och vara enkel att memorera eller läsa upp över telefon.
- Följa namngivningsstandard, det vill säga inte innehålla specialtecken, inga stora bokstäver etc.
- Ha funnits ett tag, det är ett tecken på seriositet för en sökmotor.
- Innehålla något unikt, med andra ord ska det inte finnas flera sätt att nå exakt samma innehåll.
- Vara funktionell. Om adressen är hierarkisk ska det gå att sudda delar av adressen för att nå en högre nivå i strukturen.
- Ge korrekt statuskod enligt HTTP. Saknas sidan är det 404 som gäller, är den flyttad skall man hänvisa vidare med status 301.
- Ha någon form av rättstavningsfunktion så den klarar av felaktigheter som www som prefix, med eller utan avslutande snedstreck etc.
Det här behöver förstås slå igenom i designen av ett webbsystem och finnas med som krav vid upphandling. Alla som möjligen kan påverka adresser behöver informeras om tänkt URL-standard. Webbredaktörer borde egentligen lägga mer tid på adressen än huvudrubriken då adressen inte är något de ska kunna ändra utan vidare vid ett senare tillfälle.
Dokumentera gärna din syn på en bra URL-strategi och försök följa den. Har du redaktörer så är det bra att få med dem på tåget, särskilt för tidsbunden information som kalenderhändelser och nyheter. Inte sällan även för uppladdade filer som ofta laddas upp utan mycket reflektion kring filens namn vilket nästan alltid följer med i URL:en.
Vanliga svepskäl för att bryta inarbetade URL:ar
Som rubriken antyder anser jag att de flesta tillfällen det här med brutna adresser kommer på tal så är det svepskäl man får höra från någon som prioriterat bort sina besökares bästa. Men egentligen kan man inte klandra någon, de flesta tycks inte själva ha funderat igenom detta och en URL-strategi har jag aldrig stött på under mina 15 år i branschen – jag får väl skriva en själv förr eller senare.
Nu kommer några exempel på vad jag fått höra som orsak och förslag på hur man kan jobba.
”Men vi har ju lagt ner webbplatsen, numera finns samma info där…”
Att webbplatser läggs ner är inget konstigt. Ibland ersätts de dock av en annan webbplats, på en annan domän, och då har man chansen att återvinna lite av kraften från de inarbetade adresserna.
Här finns några vanliga varianter på hur man inte bör hantera sina gamla adresser:
- Oavsett efterfrågad adress skickas besökaren till nya webbplatsens startsida.
- Enbart om besökaren anslöt till den gamla startsidan kommer denne till nya startsidan. Alla adresser utom den gamla startsidan är döda.
- Hänvisningen från gamla URL:ar är tillfällig och efter något år slutar hänvisningen att fungera då ingen tror att de används längre.
Drabbar den första varianten dig blir du säkert förvånad eller irriterad, särskilt om du har bråttom. Det var inte riktigt vad du hade hoppats på. Om besökaren ska skickas vidare utan förvarning måste den nya sidan leva upp till samma behov som den efterfrågade sidan, annars måste det meddelas vad som har hänt med den gamla sidan.
Baserat på vilka sidor som är populära eller viktiga av annan anledning bör man hjälpa besökaren vidare. Mer om det senare.
”Vi bytte publiceringssystem och det nya klarade inte av…”
Kravet på ett nytt publiceringssystem bör vara både att det kan ta hand om de gamla adresserna, vilket inte är så krångligt som man kan tro, och att de nya inte innehåller någon form av systemstandard. Många statliga aktörer valde EPiServer i början på 2000-talet och då etablerades en systemstandard i form av en undermapp med designmallar, som grädde på moset kom sidmallens namn och sidan ID-nummer med i adressen.

Adresser som www.kommun.se/kommuntemplates/Page____67241.aspx var vanliga och kan fortfarande ses i länkar ibland. Tänk dig användbarheten på de adresserna om du ska berätta det för någon annan muntligen. Hur många understreck är det? Kommer du ihåg adressen till imorgon?
Vid en uppgradering till en nyare version av EPiServer, som hade vettigare URL:ar, eller om man nu bytte publiceringssystem så fanns inarbetade, fula, adresser att ta hand om över lång tid.
”De gamla adresserna var så obegripliga, de nya är läsvänliga”
Utmärkt. Om intresset för adressernas kvalitet är så stort bör man vara en hygglig prick och ta hand om alla gamla adresser även fast de var fula. De gamla fula adresserna innehåller ofta någon siffra som identifierar vilken information som ska hämtas ur en databas, troligen kan denna siffra, eller hela adressen, matas in i ert nya webbsystem så hamnar besökaren rätt även efter ett byte.
Att ta hand om gamla fula adresser, eller åtminstone att ett manuellt verktyg finns, är något som seriösa webbyråer erbjudit i åratal. Det gäller mest att förstå att det är möjligt, att det är vettigt och se till att kravställa funktionen.
”Vi arkiverar inaktuella sidor löpande”
Att löpande rensa sina publicerade sidor är hedersvärt på sitt sätt, men vad är anledningen? Ibland får man höra att nyheter bör tas bort för att de är inaktuella och i vägen för äldre nyheter, att kalenderhändelser bör tas bort strax efter att händelsen är överstökad.
Det man inte tänkt på då är att webben är ett utmärkt arkiv och att informationen kan ha ett värde på sikt även fast dess aktualitet minskar. Är det möjligtvis problem med informationsstrukturen som gör att man irriterar sig på detta innehåll? Gör det livet svårare när man använder sökmotorn?
Ett motargument skulle vara att via metadata instruera sökmotorn att innehållet inte är särskilt viktigt, eller att rent utav be sökmotorn låta bli att indexera sidan. Ett annat är att man kanske inte tänkt till riktigt med exempelvis utformningen av nyhetslistan eller kalenderfunktionen. Nyhetslistefunktionen kan vidareutvecklas till att ignorera nyheter med ett utgångsdatum vilket skulle ge redaktören ett alternativ till att kasta nyheten i soptunnan för att gömma undan den.
Kalenderhändelsens sidmallar kanske borde designas om med ett före-, under- och efterperspektiv. Före händelsen kanske varje kalenderhändelses sida fokuserar på att informera, ge fakta och uppmuntra till att anmäla sig. Under händelsen kan webbplatsen automatiskt växla till att guida de som inte hittar fram, primärt, men komplettera med ombokningar eller andra förändringar och tipsa om hashtaggar på Twitter etc. Efter händelsen kanske en sammanställning av dokument, tagna bilder och det bästa av vad deltagarna lagt ut publikt på nätet vore bra.
Se ovan som inspiration till vad du kan göra istället för att kasta en sida i papperskorgen – och därmed döda en etablerad URL – det finns säkert en smart lösning som gör din webbplats ännu bättre.
Det är också ok att skriva ut på en sida att den är inaktuell och arkiverad. Hellre en varnande text på sidan och lite svårare att hitta än att den raderas.
Ok, hur gör man då?
Precis som det idag är självklart att en och samma adress ska fungera oavsett om besökaren ansluter med en mobil, surfplatta eller skrivbordsdator bör det vara lika självklart att en adress är giltig överallt. Det som går att visa upp ska visas upp.
I en allt mer digital värld där man samarbetar över gränserna är det rimligt att alla adresser, URL:ar, fungerar oavsett om jag sitter på arbetsgivarens nät eller utanför. Sitter jag på fel nät, eller URL:en pekar på ett skyddat nät, så bör jag få ta del av det som passar min åtkomstnivå. Den nivån kan säkert vara lika med ingen alls ibland men tänk dig en URL till en nyhet på intranätet hos en statlig organisation, den har du rätt att läsa så varför inte designa tekniken därefter?
Några saker ska ha extraordinärt god anledning för att få lov att finnas i en URL:
- Skribentens namn. Det är inte givet att skribenten kommer vara den som tar hand om denna adress under hela dess levnad.
- Ämnen och annan form av kategorisering. Detta är nog den knepigaste varianten då det ofta känns framtidssäkert att klassificera sitt innehåll. Bra att ha i bakhuvudet är att ordet för denna klassificering tenderar till att leva kortare än innebörden av klassificeringsordet. Här kommer de extremt vanligt förekommande hierarkiska adresser in. Vad ska hända med undersidornas URL:ar om huvudsidan får ny URL?
- Status på innehållet.Informations status förändras, lika bra att utelämna det ur adressen.
- Filändelser som .html, .php och liknande för webbsidor. För uppladdade filer är dock filextension okej, men även där gäller det att tänka till. Problemet med .php och liknande är att de har med systemet att göra, om man byter systemet kan man tvingas bryta samtliga inarbetade adresser.
- Påtvingade mappnamn eller spår av systemstandarder. Förr i tiden såg man mappnamn som /cgi/ men numera syns ofta /cms-templates/ eller annat som inte direkt tillför något.
- Åtkomstnivåer för information. Det är oftast inte så långsiktigt att ha åtkomstgruppers namn i adresser då namnet på dessa grupper kan ändras inom den tid en URL borde få leva och det kan ställa till det om man kommer över en adress för en annan åtkomst än den man själv tillhör.
- Datum för när innehållet skapades. Det är inga konstigheter när det handlar om mötesanteckningar, då är datum rent utav bra, men annars så ger datum i en URL sken av att informationen är gammal och inte uppdateras. Det är inte bra. En URL ska vårdas, ambitionen ska vara att den är aktuell och det bör synas i URL:en.
URL:ar i trycksaker och digitala utskick
Är det material som ska skickas ut i tryckt format, kommer det hamna utom din kontroll likt innehållet i ett nyhetsbrev eller liknande? Om du inte har kontroll över platsen du länkar till så du kan göra justeringar i efterhand finns anledning att använda en URL-tjänst. Detta finns som tjänster på nätet eller så kan man sätta upp sin egen tjänst. Flera av de populära tjänsterna stödjer att du kan använda ditt egna korta domännamn eller så kör man med en domän tjänsten erbjuder. Skillnaden ligger i hur mycket kontroll man önskar.
Man skapar en adress för en viss tänkt användning, kopplar till var adressen ska hänvisa och sedan är adressen redo för användning. En genväg där målet kan bytas ut i administrationsgränssnittet för den tjänst du kör och adressen man använt förblir densamma. Inte nog med det, man får också statistik på användningen av adressen, vilket kan vara allt från enkel besöksräkning till rätt avancerad analys.
Om du nu tvingas skrota adresser
Om du nu måste bryta en massa adresser på din webbplats, se då till att göra en ordentlig webbanalys innan så du vet vad du kan ställa till med. Det kanske inte är värt det.
En genomtänkt arkiveringslösning är ditt alternativ i denna tråkiga situation. Mitt förslag är att alla dödade adresser ska leda till en så kallad 404-sida som informerar om att sidan inte längre finns. Hur en sådan sida kan utformas hittar du lite senare i denna bok.
404-sidan i sig behöver leva länge och ta hand om döda adresser, vilket ibland är hela domäner som lagts ner. Förutom att man på något gemensamt sätt tar hand om vilsna besökare bör statistik samlas in för att se vilka av de tidigare använda adresserna som anropas mest. Är det tillräckligt många som besöker en nedlagd adress och en ny motsvarande finns är det en god idé att skicka de besökarna vidare direkt – det borde inte vara besökarens problem att ni bröt länkarna.
Förutom att manuellt knyta samman populära nedlagda adresser till nya fungerande kan man använda sökmotorteknik för att ge kvalificerade gissningar om en ny motsvarande sida. Säg exempelvis att Riksdagen skrotar samtliga inarbetade adresser och en besökare använder en länk för att läsa mer om en enskild riksdagsledamot.

Följande URL är den som använts men inte längre fungerar i detta hypotetiska exempel:
http://www.riksdagen.se/sv/ledamoter-partier/Hitta-ledamot/Ledamoter/Pehrson-Johan-0224712677012/
Den mest uppenbara lösningen är att titta på adressen och inse att den innehåller saker som beskriver sidan, nämligen:
- ledamoter partier Hitta ledamot Ledamoter Pehrson Johan. Ord som kan användas som nyckelord till en automatisk sökning bakom kulisserna på 404-sidan som då kan ge förslag.
- 0224712677012 vilket kan vara ett identifierande nummer som går att använda för att koppla till en ny adress. Om så är fallet vet bara de som hanterar webbplatsen, men vore det du är det värt att kolla upp var numret kommer ifrån och om det kan användas.
I de fall man vill rädda en driva av gamla adresser, och vet exakt hur man ska göra, kan man för exemplet ovan skapa en omdirigeringsregel på 404-sidan som gäller alla adresser under /sv/ledamoter-partier/Hitta-ledamot/Ledamoter/ och skickar besökarna vidare till motsvarande ny adress. Rent tekniskt bör denna omdirigering ske innan ett 404-meddelande skickas från webbservern, men det kan du ta upp med en utvecklare om det blir aktuellt.
Om ingen given omdirigeringsregel finns är det värt att plocka fram några av de bästa sökträffarna och tala om för besökaren att den information de sökte möjligen kan finnas bland dessa förslag. Om man på Riksdagens sida använder en sökfråga med alla orden ur adressen till riksdagsledamotens sida kommer sökmotorn faktiskt hjälpa till. Den typen av sökningar kan göras av 404-sidan och presenteras istället för att lämna besökaren i sticket.

Jag hoppas att allt kring informationsarkitektur inte tog knäcken på dig. Nu kommer det lite mer lättsamma saker då vi härnäst går igenom webbdesign.
Fortsätt läsningen i kapitel 3 – om webbdesign ›